Know Streaming

Know Streaming 源码编译打包手册
1、环境信息
系统支持
windows7+、Linux、Mac
环境依赖
- Maven 3.6.3 (后端)
- Node v12.20.0/v14.17.3 (前端)
- Java 8+ (后端)
- Git
2、编译打包
整个工程中,除了km-console为前端模块之外,其他模块都是后端工程相关模块。
因此,如果前后端合并打包,则打对整个工程进行打包;如果前端单独打包,则仅打包 km-console 中的代码;如果是仅需要后端打包,则在顶层 pom.xml 中去掉 km-console模块,然后进行打包。
具体见下面描述。
2.1、前后端合并打包
- 下载源码;
- 进入
KS-KM工程目录,执行mvn -Prelease-package -Dmaven.test.skip=true clean install -U命令; - 打包命令执行完成后,会在
km-dist/target目录下面生成一个KnowStreaming-*.tar.gz的安装包。
2.2、前端单独打包
- 下载源码;
- 跳转到 前端打包构建文档 按步骤进行。打包成功后,会在
km-rest/src/main/resources目录下生成名为templates的前端静态资源包; - 如果上一步过程中报错,请查看 FAQ 第 8.10 条;
2.3、后端单独打包
- 下载源码;
- 修改顶层
pom.xml,去掉其中的km-console模块,如下所示;
<modules>
<!-- <module>km-console</module>-->
<module>km-common</module>
<module>km-persistence</module>
<module>km-core</module>
<module>km-biz</module>
<module>km-extends/km-account</module>
<module>km-extends/km-monitor</module>
<module>km-extends/km-license</module>
<module>km-extends/km-rebalance</module>
<module>km-task</module>
<module>km-collector</module>
<module>km-rest</module>
<module>km-dist</module>
</modules>
- 执行
mvn -U clean package -Dmaven.test.skip=true命令; - 执行完成之后会在
KS-KM/km-rest/target目录下面生成一个ks-km.jar即为 KS 的后端部署的 Jar 包,也可以执行mvn -Prelease-package -Dmaven.test.skip=true clean install -U生成的 tar 包也仅有后端服务的功能;
2.1、单机部署
风险提示
⚠️ 脚本全自动安装,会将所部署机器上的 MySQL、JDK、ES 等进行删除重装,请注意原有服务丢失风险。
2.1.1、安装说明
- 以
v3.0.0-beta.1版本为例进行部署; - 以 CentOS-7 为例,系统基础配置要求 4C-8G;
- 部署完成后,可通过浏览器:
IP:PORT进行访问,默认端口是8080,系统默认账号密码:admin/admin2022_。 v3.0.0-beta.2版本开始,默认账号密码为admin/admin;- 本文为单机部署,如需分布式部署,请联系我们
软件依赖
| 软件名 | 版本要求 | 默认端口 |
|---|---|---|
| MySQL | v5.7 或 v8.0 | 3306 |
| ElasticSearch | v7.6+ | 8060 |
| JDK | v8+ | - |
| CentOS | v6+ | - |
| Ubuntu | v16+ | - |
2.1.2、脚本部署
在线安装
# 在服务器中下载安装脚本, 该脚本中会在当前目录下,重新安装MySQL。重装后的mysql密码存放在当前目录的mysql.password文件中。
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/deploy_KnowStreaming-3.0.0-beta.1.sh
# 执行脚本
sh deploy_KnowStreaming.sh
# 访问地址
127.0.0.1:8080
离线安装
# 将安装包下载到本地且传输到目标服务器
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1-offline.tar.gz
# 解压安装包
tar -zxf KnowStreaming-3.0.0-beta.1-offline.tar.gz
# 执行安装脚本
sh deploy_KnowStreaming-offline.sh
# 访问地址
127.0.0.1:8080
2.1.3、容器部署
2.1.3.1、Helm
环境依赖
Kubernetes >= 1.14 ,Helm >= 2.17.0
默认依赖全部安装,ElasticSearch(3 节点集群模式) + MySQL(单机) + KnowStreaming-manager + KnowStreaming-ui
使用已有的 ElasticSearch(7.6.x) 和 MySQL(5.7) 只需调整 values.yaml 部分参数即可
安装命令
# 相关镜像在Docker Hub都可以下载
# 快速安装(NAMESPACE需要更改为已存在的,安装启动需要几分钟初始化请稍等~)
helm install -n [NAMESPACE] [NAME] http://download.knowstreaming.com/charts/knowstreaming-manager-0.1.5.tgz
# 获取KnowStreaming前端ui的service. 默认nodeport方式.
# (http://nodeIP:nodeport,默认用户名密码:admin/admin2022_)
# `v3.0.0-beta.2`版本开始(helm chart包版本0.1.4开始),默认账号密码为`admin` / `admin`;
# 添加仓库
helm repo add knowstreaming http://download.knowstreaming.com/charts
# 拉取最新版本
helm pull knowstreaming/knowstreaming-manager
2.1.3.2、Docker Compose
环境依赖
安装命令
# `v3.0.0-beta.2`版本开始(docker镜像为0.2.0版本开始),默认账号密码为`admin` / `admin`;
# https://hub.docker.com/u/knowstreaming 在此处寻找最新镜像版本
# mysql与es可以使用自己搭建的服务,调整对应配置即可
# 复制docker-compose.yml到指定位置后执行下方命令即可启动
docker-compose up -d
验证安装
docker-compose ps
# 验证启动 - 状态为 UP 则表示成功
Name Command State Ports
----------------------------------------------------------------------------------------------------
elasticsearch-single /usr/local/bin/docker-entr ... Up 9200/tcp, 9300/tcp
knowstreaming-init /bin/bash /es_template_cre ... Up
knowstreaming-manager /bin/sh /ks-start.sh Up 80/tcp
knowstreaming-mysql /entrypoint.sh mysqld Up (health: starting) 3306/tcp, 33060/tcp
knowstreaming-ui /docker-entrypoint.sh ngin ... Up 0.0.0.0:80->80/tcp
# 稍等一分钟左右 knowstreaming-init 会退出,表示es初始化完成,可以访问页面
Name Command State Ports
-------------------------------------------------------------------------------------------
knowstreaming-init /bin/bash /es_template_cre ... Exit 0
knowstreaming-mysql /entrypoint.sh mysqld Up (healthy) 3306/tcp, 33060/tcp
访问
http://127.0.0.1:80/
docker-compose.yml
version: "2"
services:
# *不要调整knowstreaming-manager服务名称,ui中会用到
knowstreaming-manager:
image: knowstreaming/knowstreaming-manager:latest
container_name: knowstreaming-manager
privileged: true
restart: always
depends_on:
- elasticsearch-single
- knowstreaming-mysql
expose:
- 80
command:
- /bin/sh
- /ks-start.sh
environment:
TZ: Asia/Shanghai
# mysql服务地址
SERVER_MYSQL_ADDRESS: knowstreaming-mysql:3306
# mysql数据库名
SERVER_MYSQL_DB: know_streaming
# mysql用户名
SERVER_MYSQL_USER: root
# mysql用户密码
SERVER_MYSQL_PASSWORD: admin2022_
# es服务地址
SERVER_ES_ADDRESS: elasticsearch-single:9200
# 服务JVM参数
JAVA_OPTS: -Xmx1g -Xms1g
# 对于kafka中ADVERTISED_LISTENERS填写的hostname可以通过该方式完成
# extra_hosts:
# - "hostname:x.x.x.x"
# 服务日志路径
# volumes:
# - /ks/manage/log:/logs
knowstreaming-ui:
image: knowstreaming/knowstreaming-ui:latest
container_name: knowstreaming-ui
restart: always
ports:
- '80:80'
environment:
TZ: Asia/Shanghai
depends_on:
- knowstreaming-manager
# extra_hosts:
# - "hostname:x.x.x.x"
elasticsearch-single:
image: docker.io/library/elasticsearch:7.6.2
container_name: elasticsearch-single
restart: always
expose:
- 9200
- 9300
# ports:
# - '9200:9200'
# - '9300:9300'
environment:
TZ: Asia/Shanghai
# es的JVM参数
ES_JAVA_OPTS: -Xms512m -Xmx512m
# 单节点配置,多节点集群参考 https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docker.html#docker-compose-file
discovery.type: single-node
# 数据持久化路径
# volumes:
# - /ks/es/data:/usr/share/elasticsearch/data
# es初始化服务,与manager使用同一镜像
# 首次启动es需初始化模版和索引,后续会自动创建
knowstreaming-init:
image: knowstreaming/knowstreaming-manager:latest
container_name: knowstreaming-init
depends_on:
- elasticsearch-single
command:
- /bin/bash
- /es_template_create.sh
environment:
TZ: Asia/Shanghai
# es服务地址
SERVER_ES_ADDRESS: elasticsearch-single:9200
knowstreaming-mysql:
image: knowstreaming/knowstreaming-mysql:latest
container_name: knowstreaming-mysql
restart: always
environment:
TZ: Asia/Shanghai
# root 用户密码
MYSQL_ROOT_PASSWORD: admin2022_
# 初始化时创建的数据库名称
MYSQL_DATABASE: know_streaming
# 通配所有host,可以访问远程
MYSQL_ROOT_HOST: '%'
expose:
- 3306
# ports:
# - '3306:3306'
# 数据持久化路径
# volumes:
# - /ks/mysql/data:/data/mysql
2.1.4、手动部署
部署流程
- 安装
JDK-11、MySQL、ElasticSearch等依赖服务 - 安装 KnowStreaming
2.1.4.1、安装 MySQL 服务
yum 方式安装
# 配置yum源
wget https://dev.mysql.com/get/mysql57-community-release-el7-9.noarch.rpm
rpm -ivh mysql57-community-release-el7-9.noarch.rpm
# 执行安装
yum -y install mysql-server mysql-client
# 服务启动
systemctl start mysqld
# 获取初始密码并修改
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
rpm 方式安装
# 下载安装包
wget https://s3-gzpu.didistatic.com/knowsearch/mysql5.7.tar.gz
# 解压到指定目录
tar -zxf mysql5.7.tar.gz -C /tmp/
# 执行安装
yum -y localinstall /tmp/libaio-*.rpm /tmp/mysql-*.rpm
# 服务启动
systemctl start mysqld
# 获取初始密码并修改
old_pass=`grep 'temporary password' /var/log/mysqld.log | awk '{print $NF}' | tail -n 1`
mysql -NBe "alter user USER() identified by 'Didi_km_678';" --connect-expired-password -uroot -p$old_pass
2.1.4.2、配置 JDK 环境
# 下载安装包
wget https://s3-gzpu.didistatic.com/pub/jdk11.tar.gz
# 解压到指定目录
tar -zxf jdk11.tar.gz -C /usr/local/
# 更改目录名
mv /usr/local/jdk-11.0.2 /usr/local/java11
# 添加到环境变量
echo "export JAVA_HOME=/usr/local/java11" >> ~/.bashrc
echo "export CLASSPATH=/usr/java/java11/lib" >> ~/.bashrc
echo "export PATH=$JAVA_HOME/bin:$PATH:$HOME/bin" >> ~/.bashrc
source ~/.bashrc
2.1.4.3、ElasticSearch 实例搭建
- ElasticSearch 用于存储平台采集的 Kafka 指标;
- 以下安装示例为单节点模式,如需集群部署可以参考:Elasticsearch 官方文档
# 下载安装包
wget https://s3-gzpu.didistatic.com/pub/elasticsearch.tar.gz
# 创建ES数据存储目录
mkdir -p /data/es_data
# 创建ES所属用户
useradd arius
# 配置用户的打开文件数
echo "arius soft nofile 655350" >> /etc/security/limits.conf
echo "arius hard nofile 655350" >> /etc/security/limits.conf
echo "vm.max_map_count = 655360" >> /etc/sysctl.conf
sysctl -p
# 解压安装包
tar -zxf elasticsearch.tar.gz -C /data/
# 更改目录所属组
chown -R arius:arius /data/
# 修改配置文件(参考以下配置)
vim /data/elasticsearch/config/elasticsearch.yml
cluster.name: km_es
node.name: es-node1
node.master: true
node.data: true
path.data: /data/es_data
http.port: 8060
discovery.seed_hosts: ["127.0.0.1:9300"]
# 修改内存配置
vim /data/elasticsearch/config/jvm.options
-Xms2g
-Xmx2g
# 启动服务
su - arius
export JAVA_HOME=/usr/local/java11
sh /data/elasticsearch/control.sh start
# 确认状态
sh /data/elasticsearch/control.sh status
2.1.4.4、KnowStreaming 实例搭建
# 下载安装包
wget https://s3-gzpu.didistatic.com/pub/knowstreaming/KnowStreaming-3.0.0-beta.1.tar.gz
# 解压安装包到指定目录
tar -zxf KnowStreaming-3.0.0-beta.1.tar.gz -C /data/
# 修改启动脚本并加入systemd管理
cd /data/KnowStreaming/
# 创建相应的库和导入初始化数据
mysql -uroot -pDidi_km_678 -e "create database know_streaming;"
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-ks-km.sql
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-job.sql
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/ddl-logi-security.sql
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-ks-km.sql
mysql -uroot -pDidi_km_678 know_streaming < ./init/sql/dml-logi.sql
# 创建elasticsearch初始化数据
sh ./bin/init_es_template.sh
# 修改配置文件
vim ./conf/application.yml
# 监听端口
server:
port: 8080 # web 服务端口
tomcat:
accept-count: 1000
max-connections: 10000
# ES地址
es.client.address: 127.0.0.1:8060
# 数据库配置(一共三处地方,修改正确的mysql地址和数据库名称以及用户名密码)
jdbc-url: jdbc:mariadb://127.0.0.1:3306/know_streaming?.....
username: root
password: Didi_km_678
# 启动服务
cd /data/KnowStreaming/bin/
sh startup.sh
5.0、产品简介
Know Streaming 是一套云原生的 Kafka 管控平台,脱胎于众多互联网内部多年的 Kafka 运营实践经验,专注于 Kafka 运维管控、监控告警、资源治理、多活容灾等核心场景,在用户体验、监控、运维管控上进行了平台化、可视化、智能化的建设,提供一系列特色的功能,极大地方便了用户和运维人员的日常使用,让普通运维人员都能成为 Kafka 专家。
5.1、功能架构
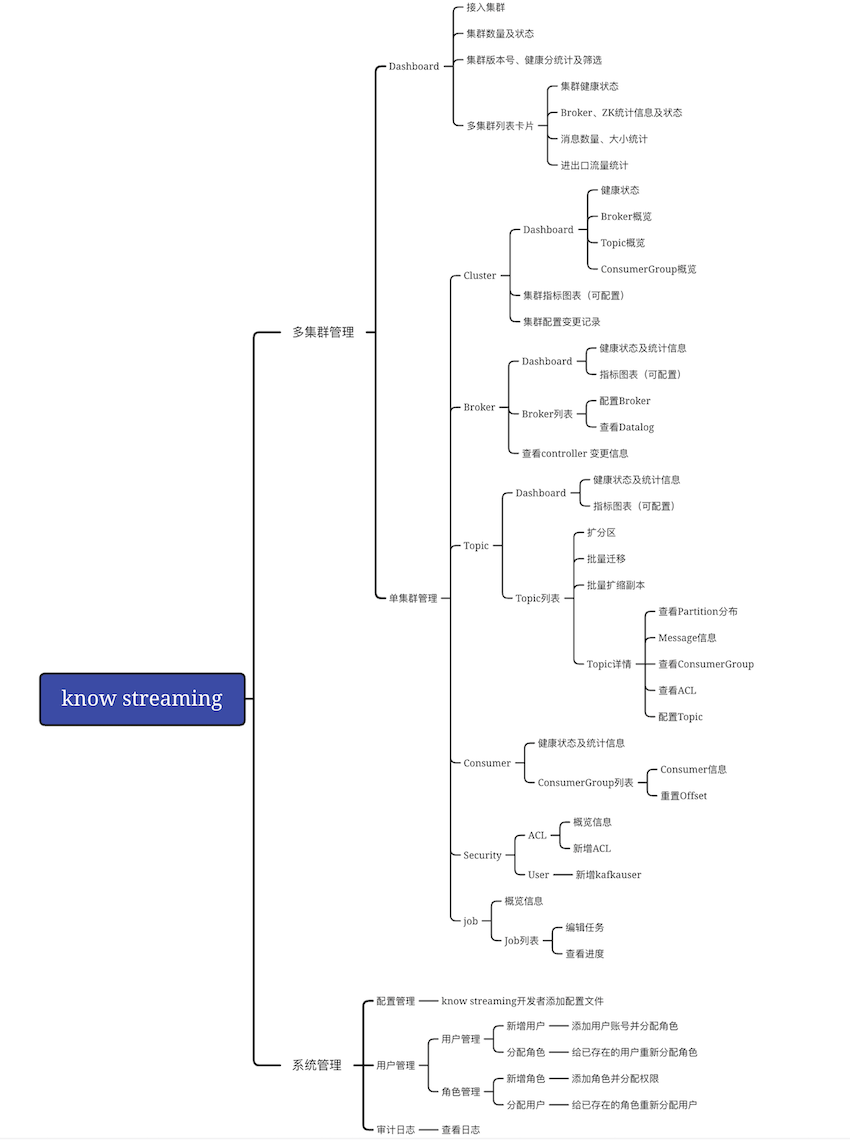
5.2、体验路径
下面是用户第一次使用我们产品的典型体验路径:
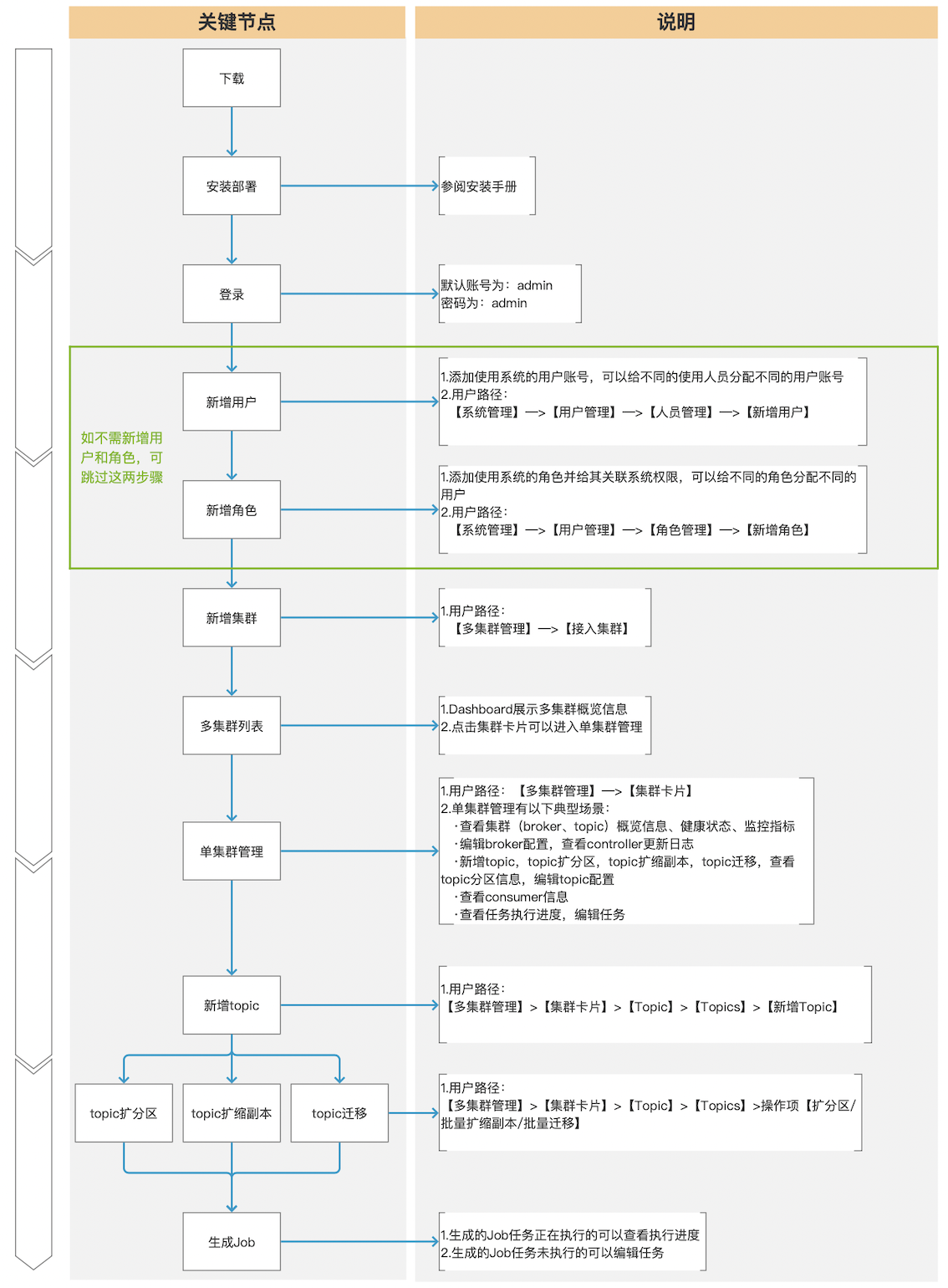
5.3、常用功能
5.3.1、用户管理
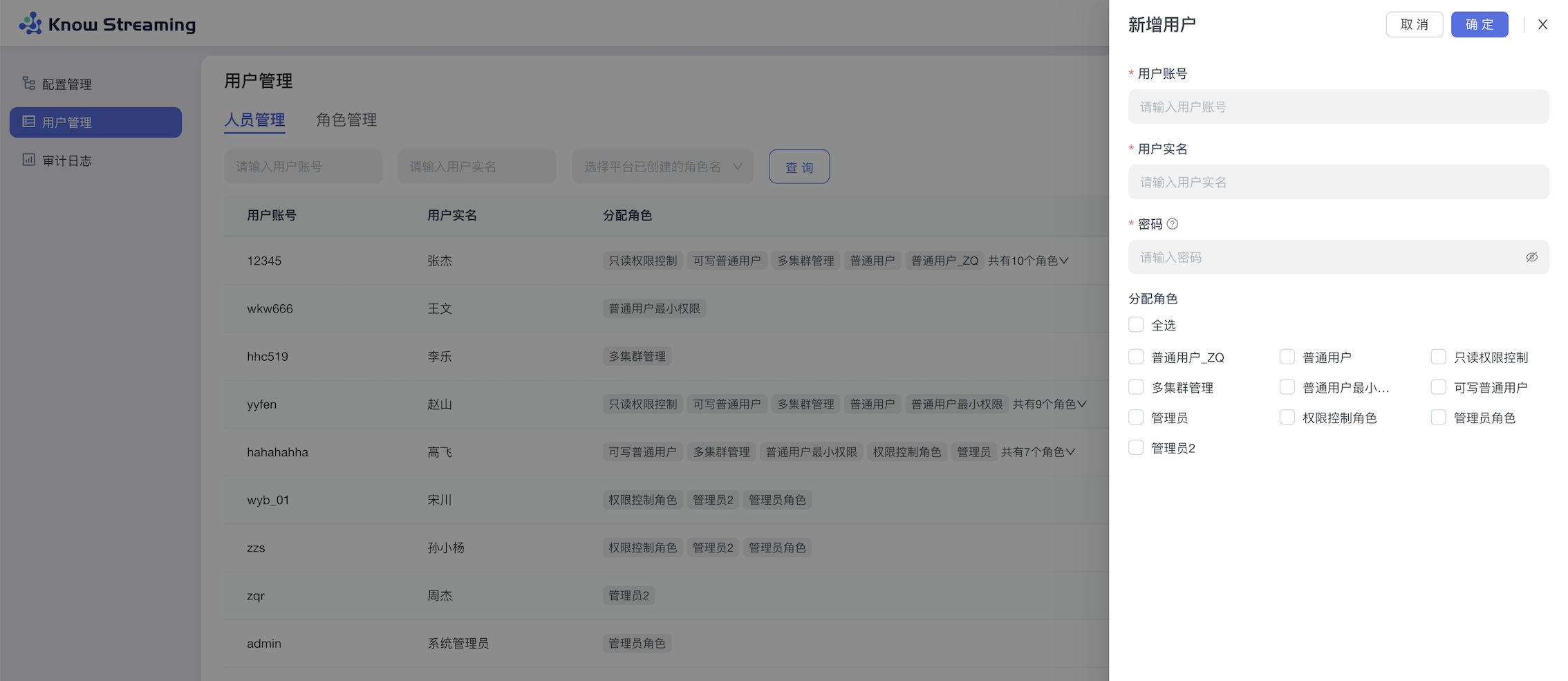
用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。下面是一个典型的场景: eg:团队加入了新成员,需要给这位成员分配一个使用系统的账号,需要以下几个步骤
步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”,输入“账号”、“实名”、“密码”,根据此账号所需要的权限,选择此账号所对应的角色。如果有满足权限的角色,则用户新增成功。如果没有满足权限的角色,则需要新增角色(步骤 2)
步骤 2:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”。输入角色名称和描述,给此角色分配权限,点击“确定”,角色新增成功
步骤 3:根据此新增的角色,参考步骤 1,重新新增用户
步骤 4:此用户账号新增成功,可以进行登录产品使用
5.3.2、接入集群
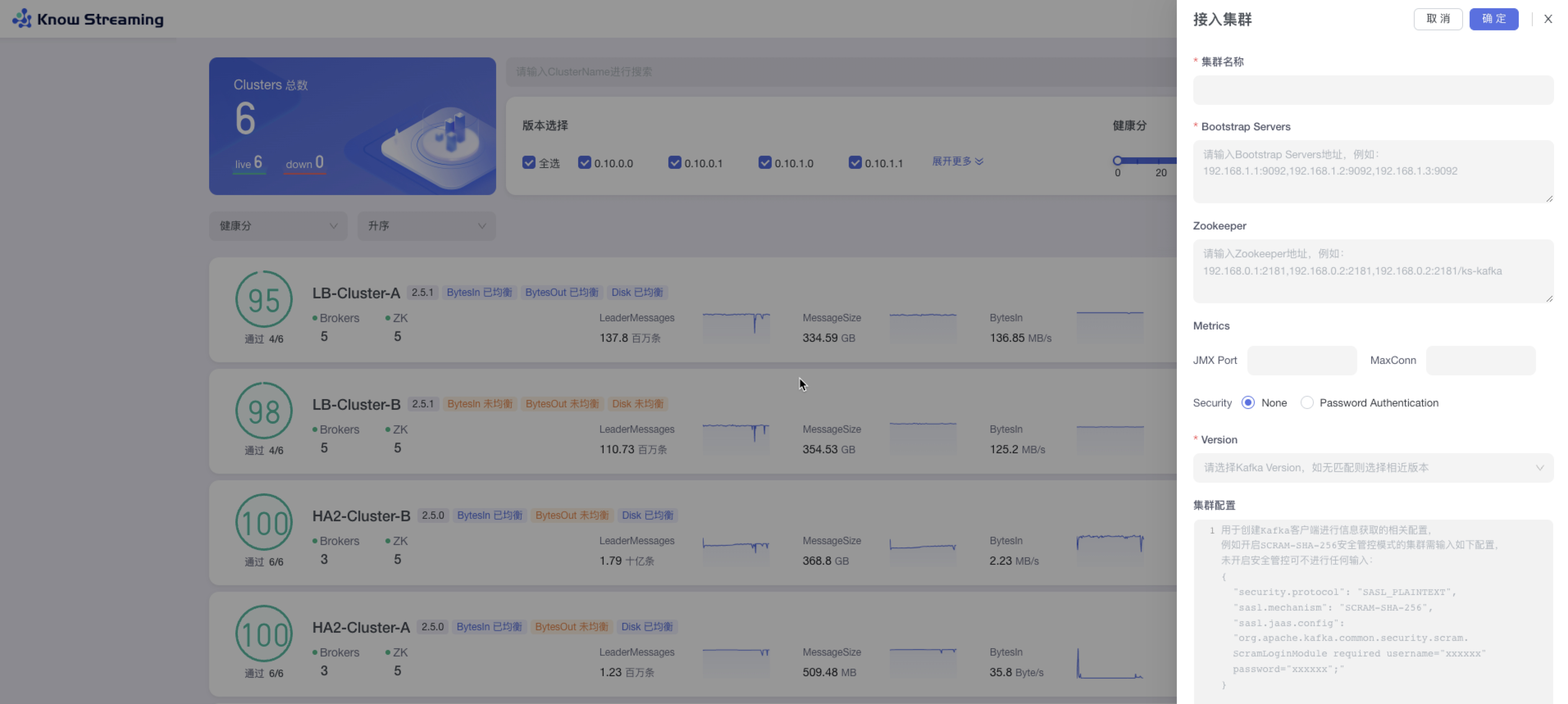
步骤 1:点击“多集群管理”>“接入集群”
步骤 2:填写相关集群信息
集群名称:支持中英文、下划线、短划线(-),最长 128 字符。平台内不能重复
- Bootstrap Servers:输入 Bootstrap Servers 地址。输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- Security:若有 JMX 账号密码,则输入账号密码
- Version:选择所支持的 kafka 版本,如果没有匹配则可以选择相近版本
- 集群配置选填:输入用户创建 kafka 客户端进行信息获取的相关配置
- 集群描述:最多 200 字符
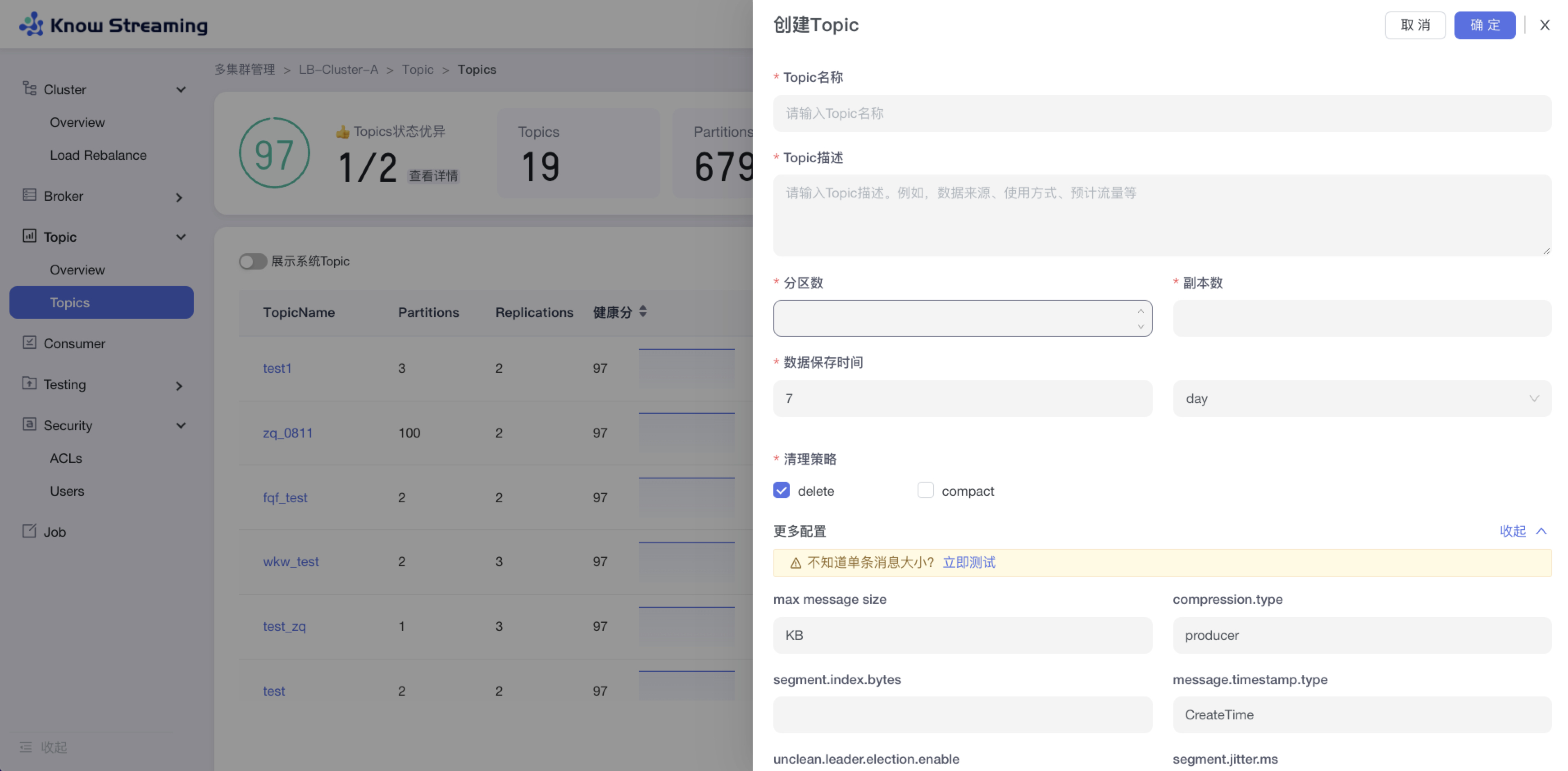
5.3.3、新增 Topic
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
步骤 4:点击“确定”,创建 Topic 完成
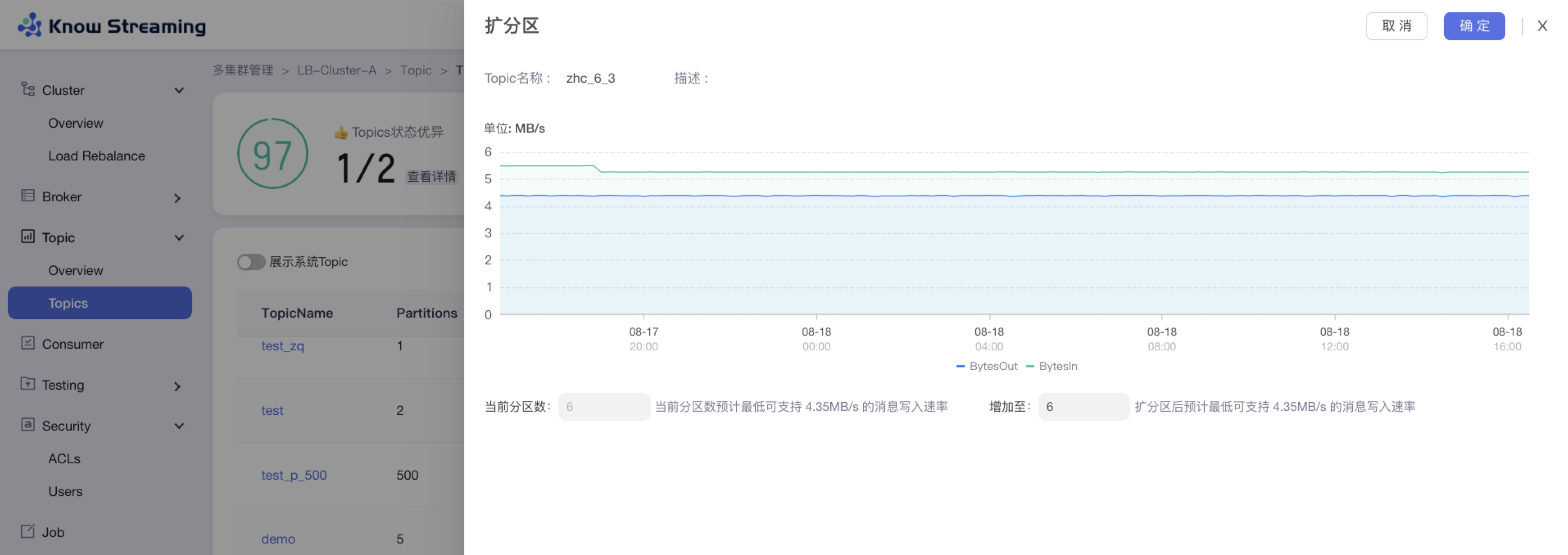
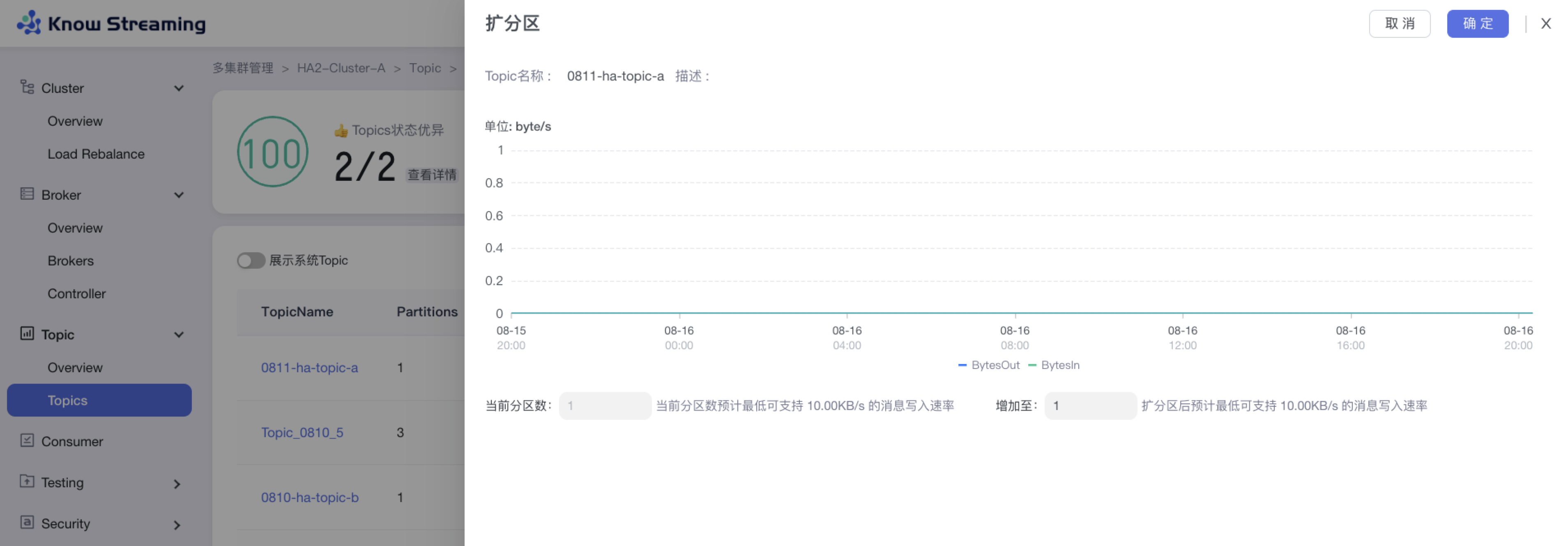
5.3.4、Topic 扩分区
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
步骤 4:点击确定,扩分区完成
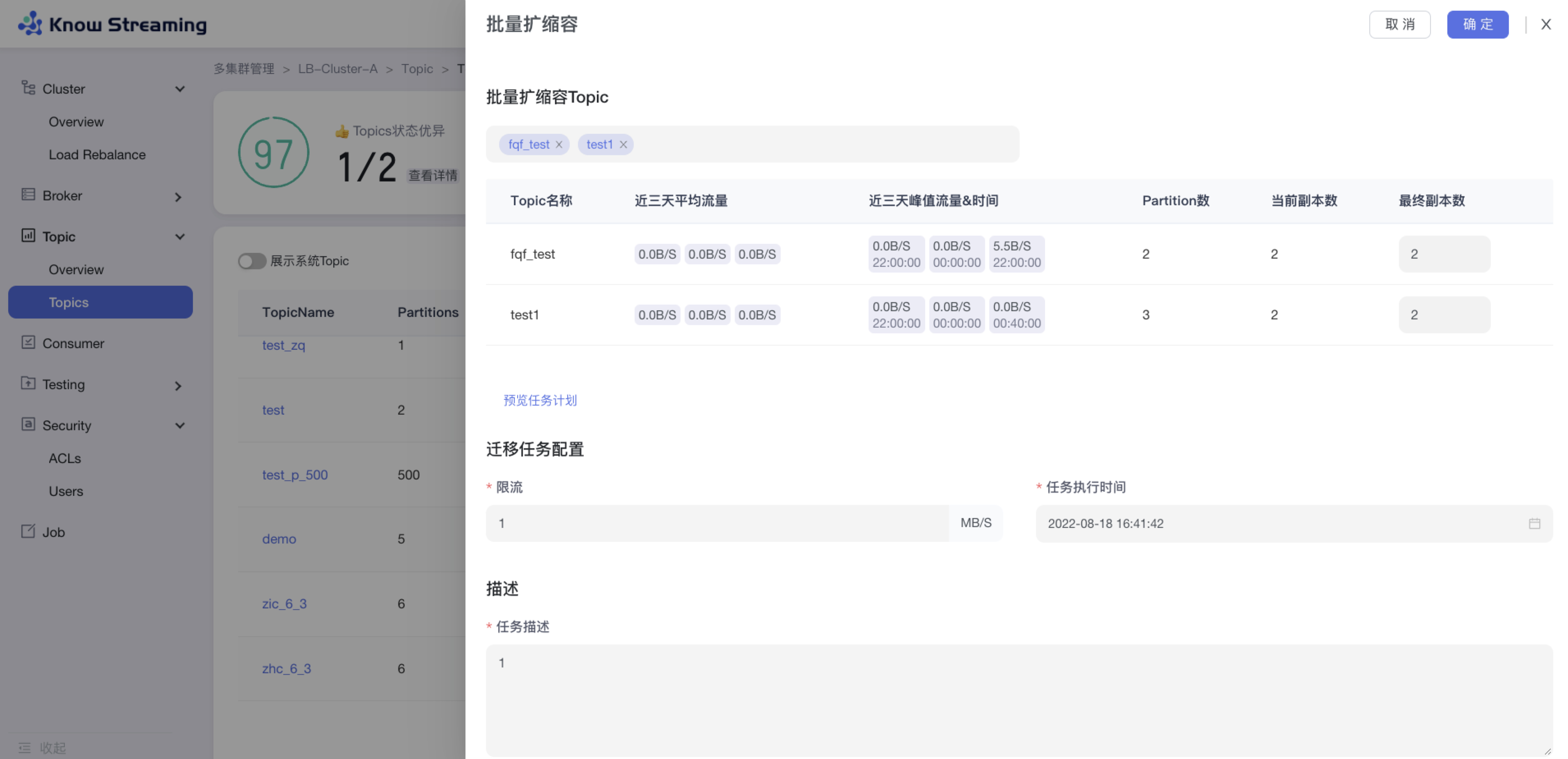
5.3.5、Topic 批量扩缩副本
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
步骤 6:输入任务描述
步骤 7:点击“确定”,创建 Topic 扩缩副本任务
步骤 8:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
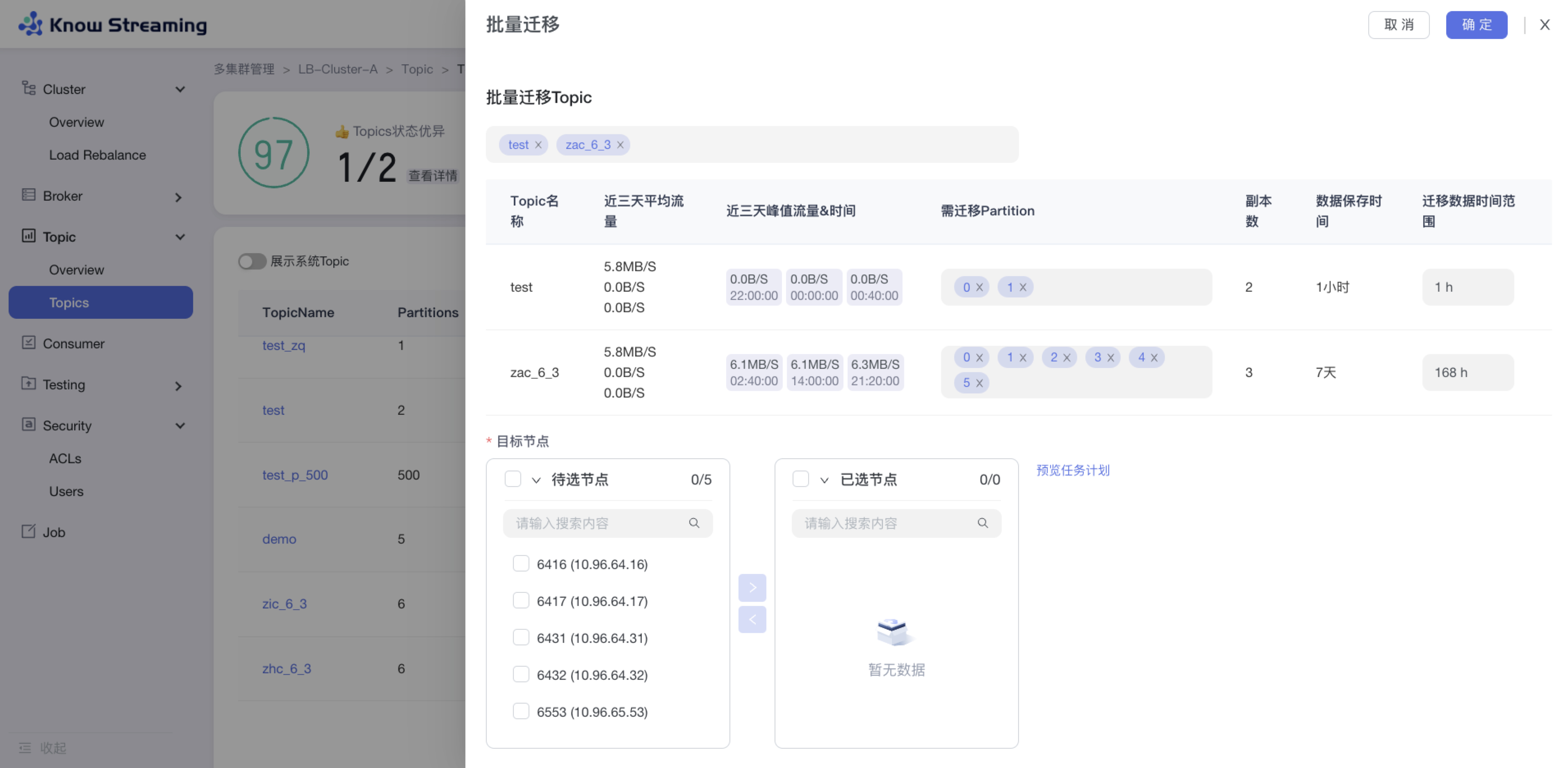
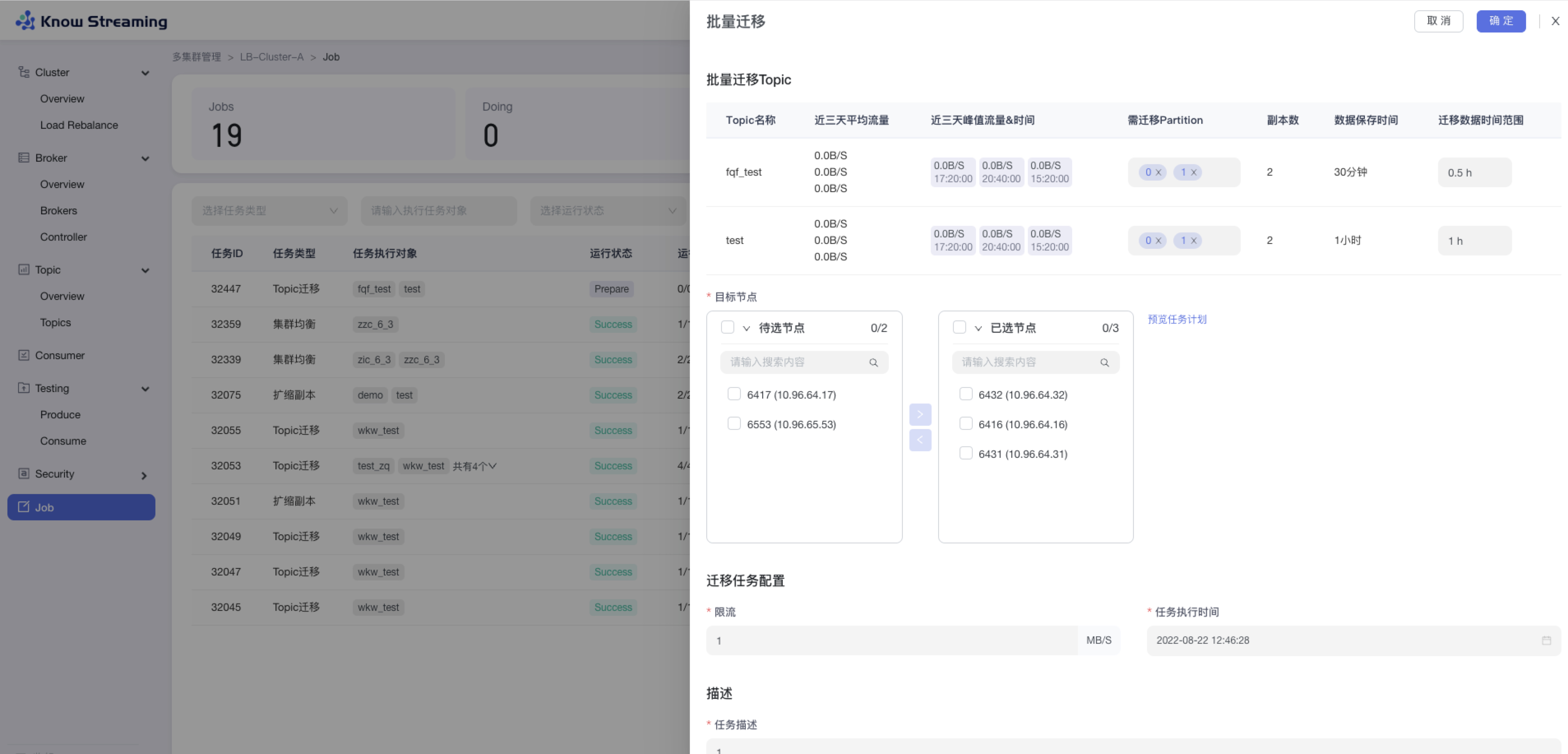
5.3.6、Topic 批量迁移
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
步骤 4:选择目标节点(节点数必须不小于最大副本数)
步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对目标 Broker ID 进行编辑
步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
步骤 7:输入任务描述
步骤 8:点击“确定”,创建 Topic 迁移任务
步骤 9:去“Job”模块的 Job 列表查看创建的任务,如果已经执行则可以查看执行进度;如果未开始执行则可以编辑任务
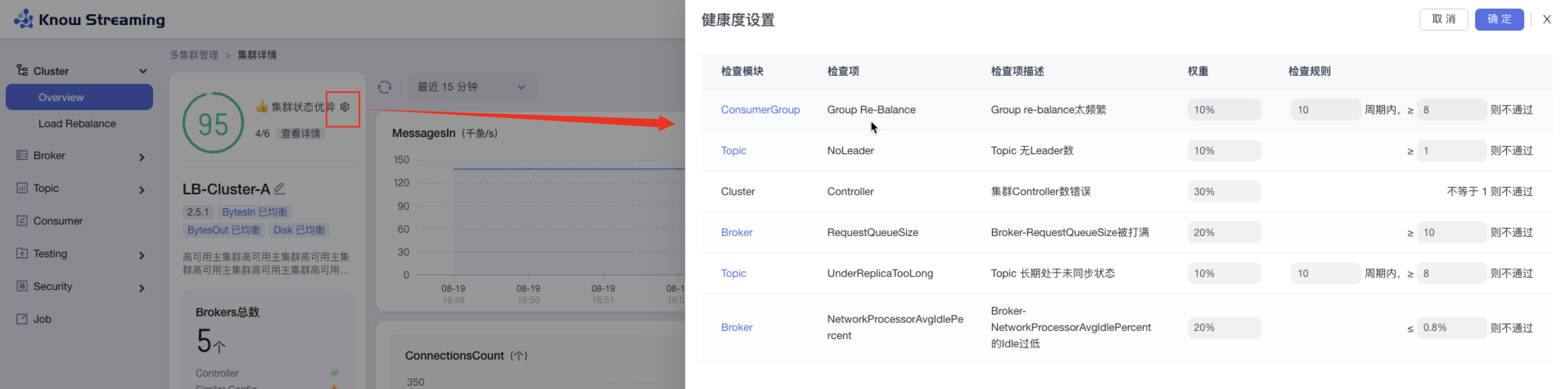
5.3.7、设置 Cluster 健康检查规则
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
步骤 3:检查规则可配置,分别为
- Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态则不通过
- ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
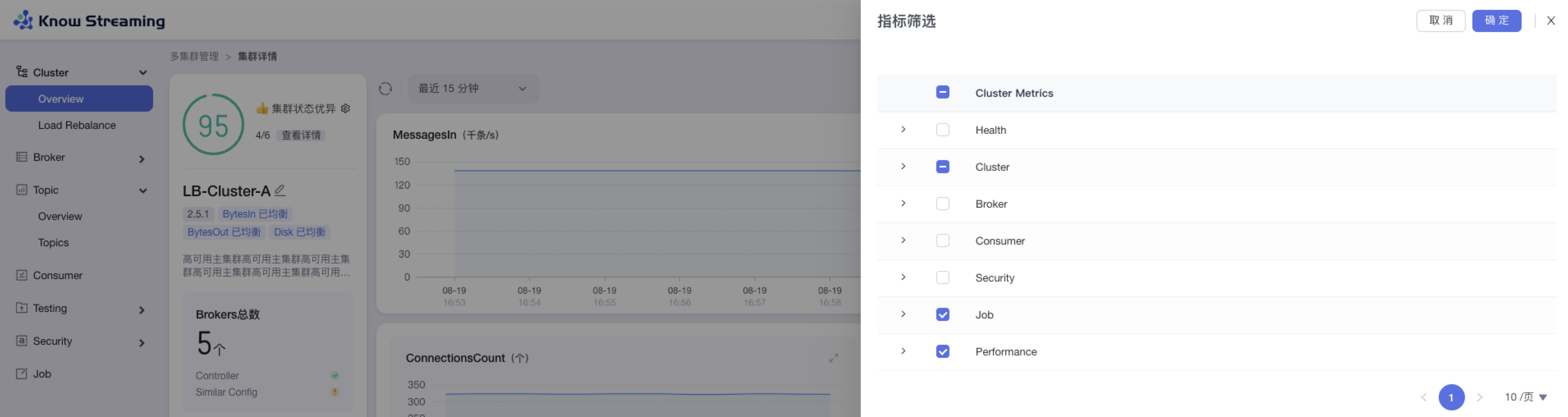
5.3.8、图表指标筛选
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
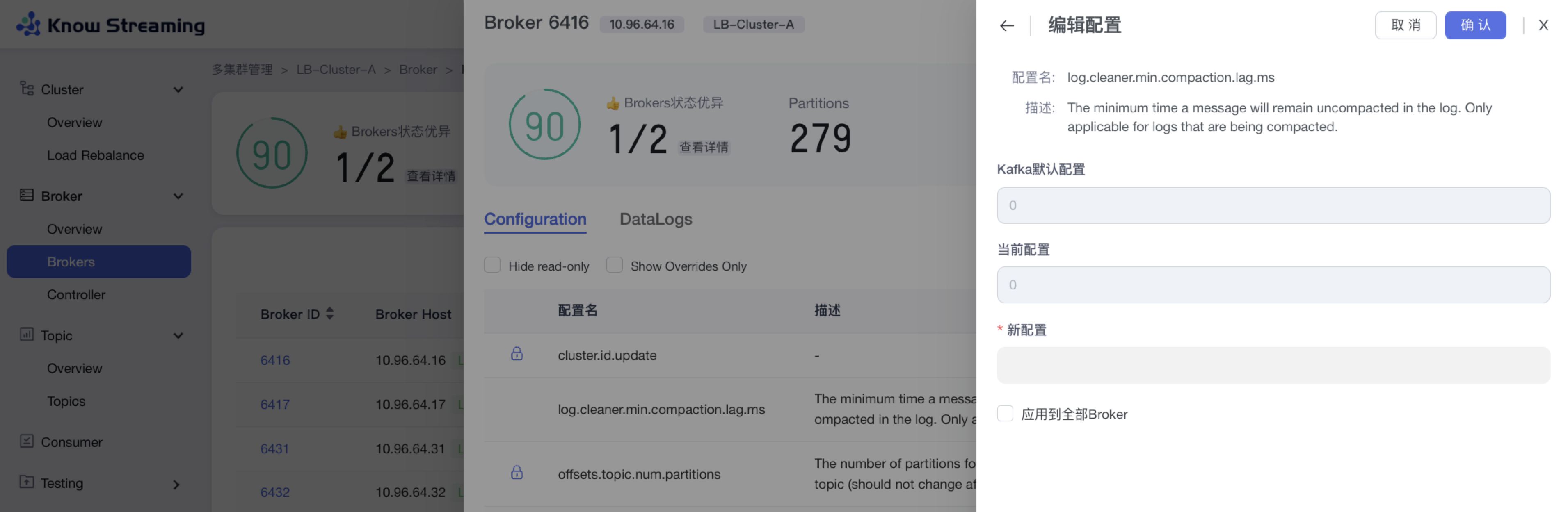
5.3.9、编辑 Broker 配置
步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
步骤 2:输入配置项的新配置内容
步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
步骤 4:点击“确认”,Broker 配置修改成功
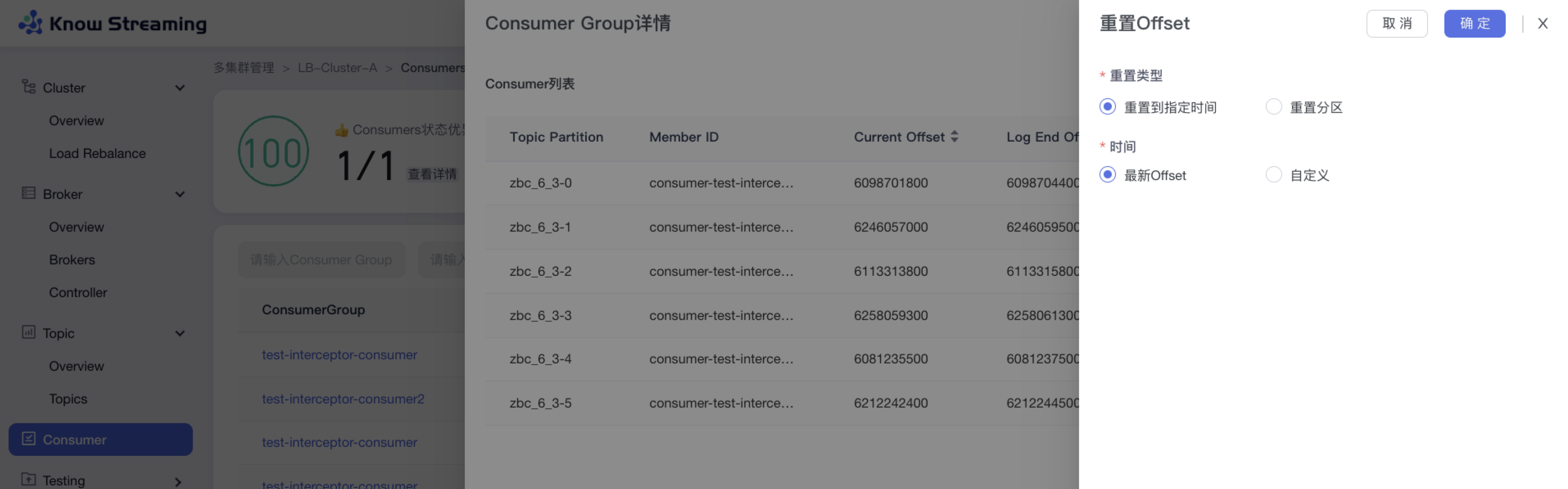
5.3.10、重置 consumer Offset
步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
步骤 4:重置分区,可选择 partition 和其重置的 offset
步骤 5:点击“确认”,重置 Offset 开始执行
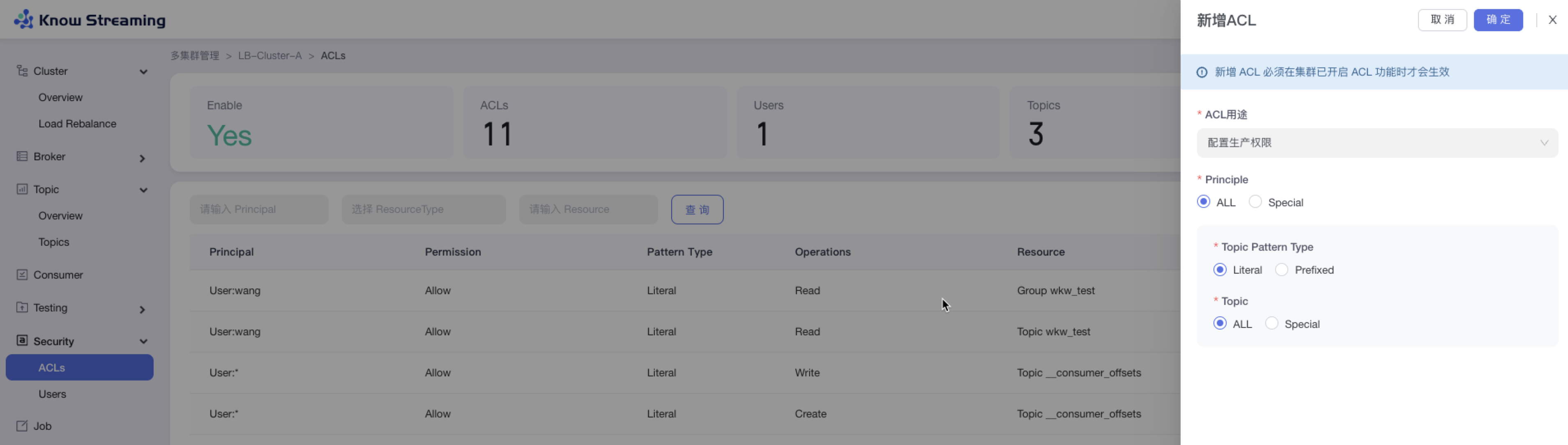
5.3.11、新增 ACL
步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
步骤 2:输入 ACL 配置参数
- ACL 用途:生产权限、消费权限、自定义权限
- 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
步骤 3:点击“确定”,新增 ACL 成功
5.4、全部功能
5.4.1、登录/退出登录
登录:输入账号密码,点击登录
退出登录:鼠标悬停右上角“头像”或者“用户名”,出现小弹窗“登出”,点击“登出”,退出登录
5.4.2、系统管理
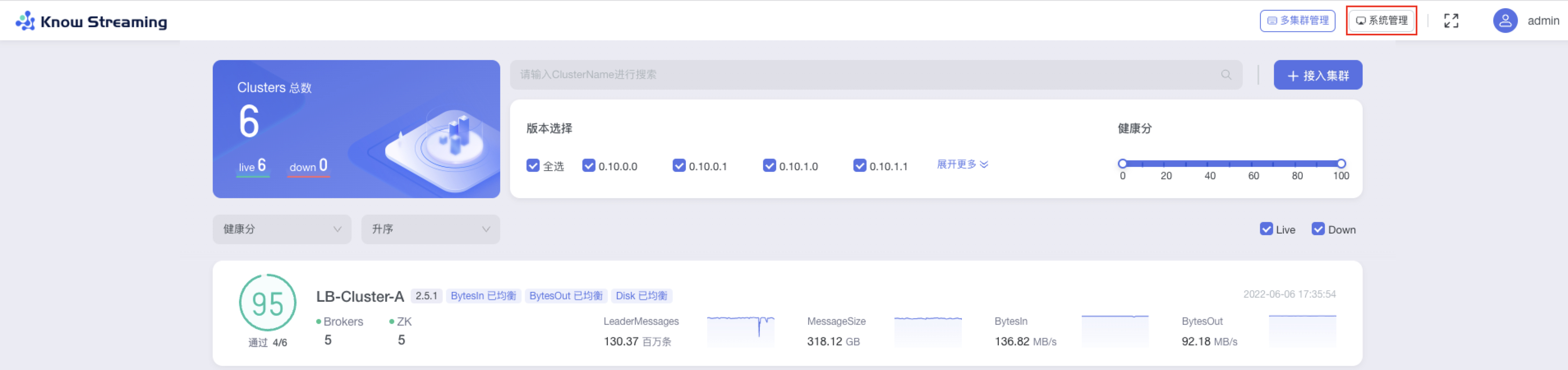
用户登录完成之后,点击页面右上角【系统管理】按钮,切换到系统管理的视角,可以进行配置管理、用户管理、审计日志查看。
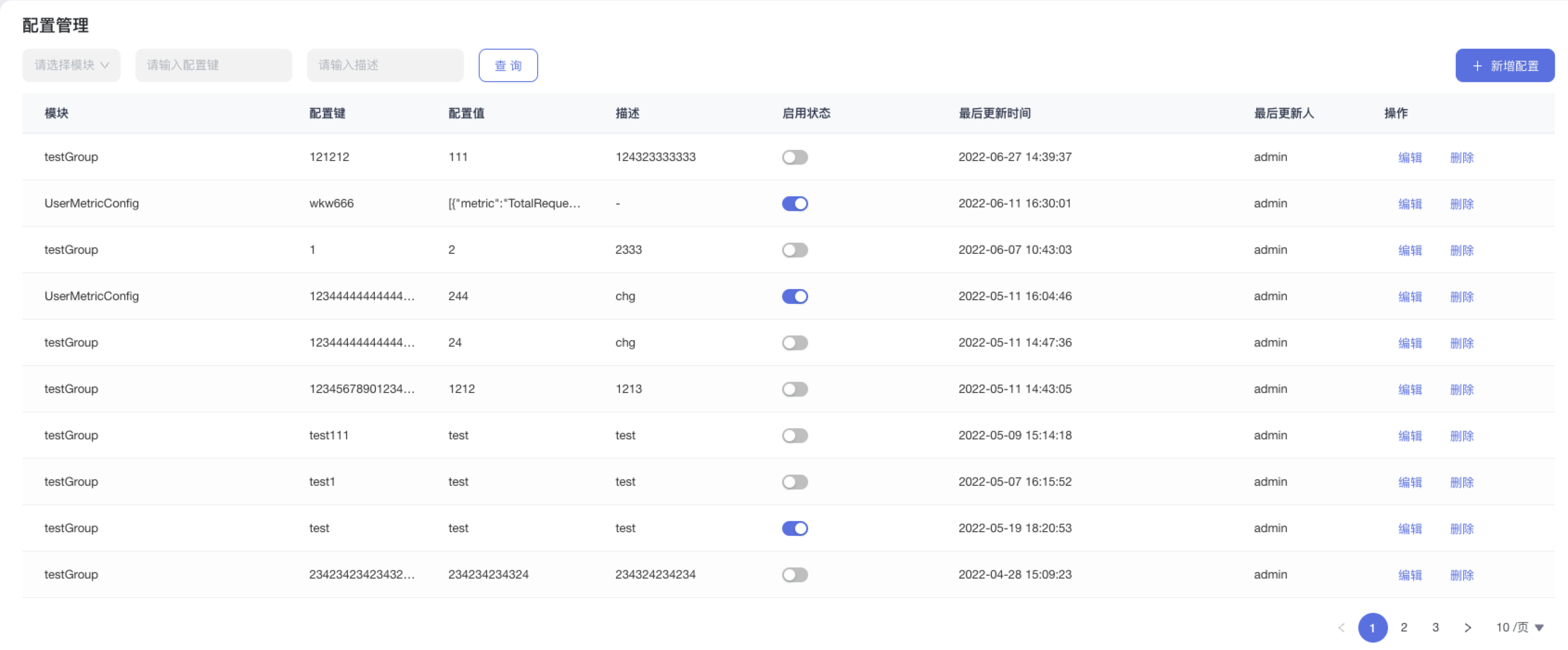
5.4.2.1、配置管理
配置管理是提供给管理员一个快速配置配置文件的能力,所配置的配置文件将会在对应模块生效。
5.4.2.2、查看配置列表
步骤 1:点击”系统管理“>“配置管理”
步骤 2:列表展示配置所属模块、配置键、配置值、启用状态、更新时间、更新人。列表有操作项编辑、删除,可对配置模块、配置键、配置值、描述、启用状态进行配置,也可删除此条配置
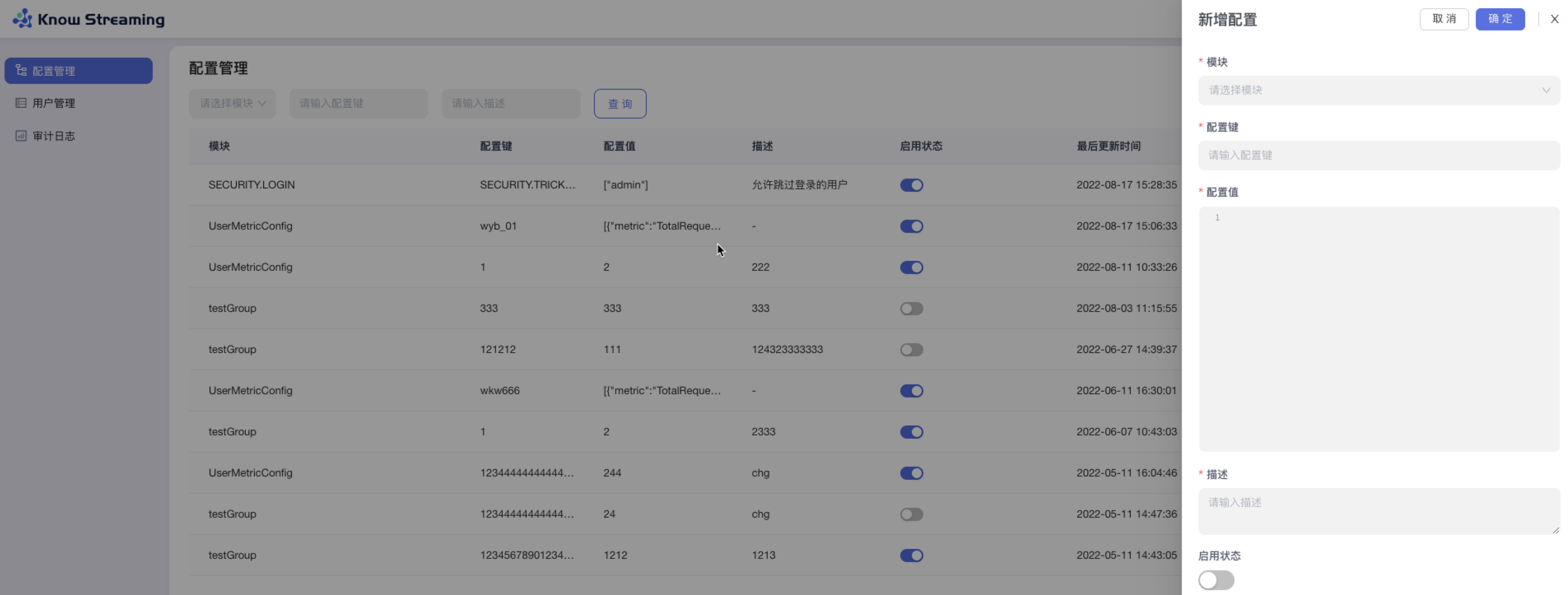
5.4.2.3、新增配置
步骤 1:点击“系统管理”>“配置管理”>“新增配置”
步骤 2:模块:下拉选择所有可配置的模块;配置键:不限制输入内容,500 字以内;配置值:代码编辑器样式,不限内容不限长度;启用状态开关:可以启用/禁用此项配置
5.4.2.4、编辑配置
可对配置模块、配置键、配置值、描述、启用状态进行配置。
5.4.2.5、用户管理
用户管理是提供给管理员进行人员管理和用户角色管理的功能模块,可以进行新增用户和分配角色。
5.4.2.6、人员管理列表
步骤 1:点击“系统管理”>“用户管理”>“人员管理”
步骤 2:人员管理列表展示用户角色、用户实名、用户分配的角色、更新时间、编辑操作。
步骤 3:列表支持”用户账号“、“用户实名”、“角色名”筛选。
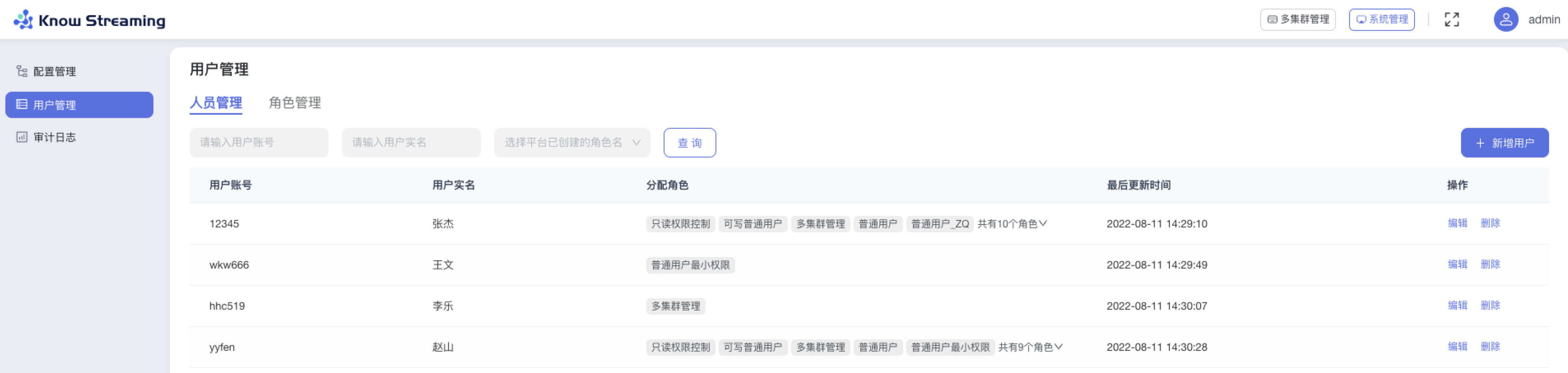
5.4.2.7、新增用户
步骤 1:点击“系统管理”>“用户管理”>“人员管理”>“新增用户”
步骤 2:填写“用户账号”、“用户实名”、“用户密码”这些必填参数,可以对此账号分配已经存在的角色。
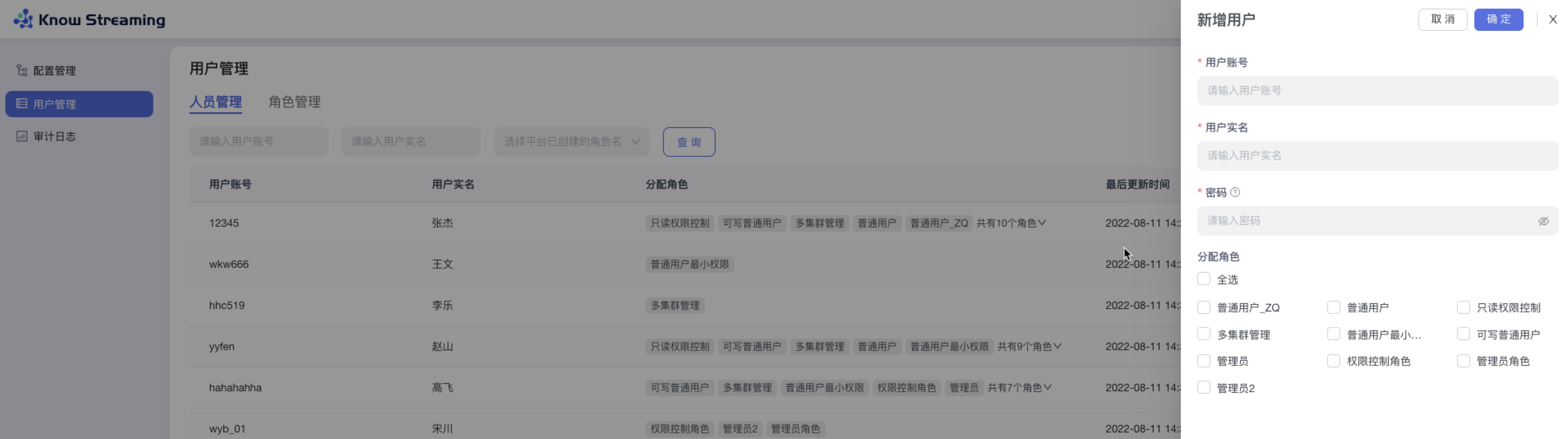
5.4.2.8、编辑用户
步骤 1:点击“系统管理”>“用户管理”>“人员管理”>列表操作项“编辑”
步骤 2:用户账号不可编辑;可以编辑“用户实名”,修改“用户密码”,重新分配“用户角色“
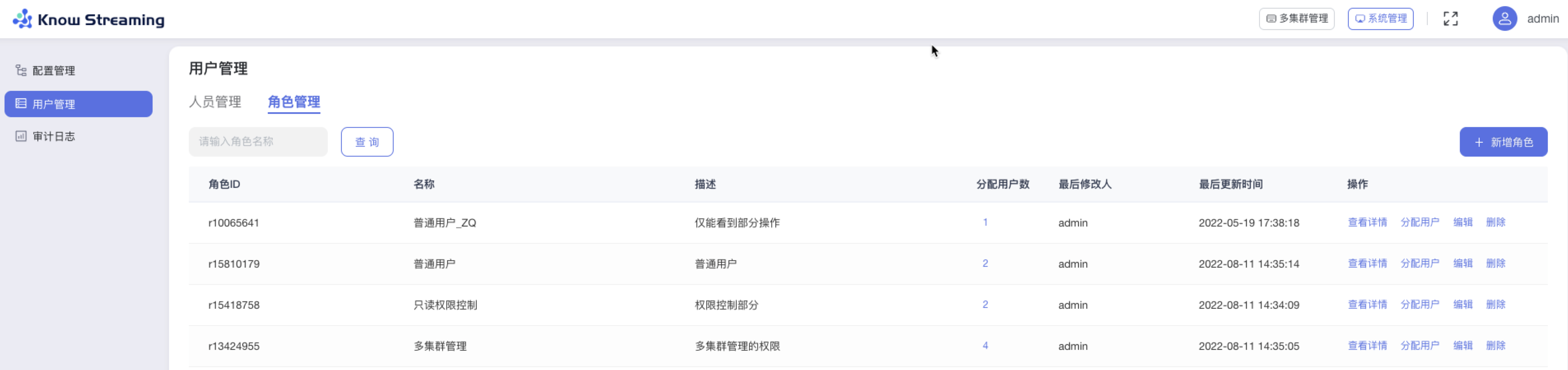
5.4.2.9、角色管理列表
步骤 1:点击“系统管理”>“用户管理”>“角色管理”
步骤 2:角色列表展示信息为“角色 ID”、“名称”、“描述”、“分配用户数”、“最后修改人”、“最后更新时间”、操作项“查看详情”、操作项”分配用户“
步骤 3:列表有筛选框,可对“角色名称”进行筛选
步骤 4:列表操作项,“查看详情”可查看到角色绑定的权限项,”分配用户“可对此项角色下绑定的用户进行增减
5.4.2.10、新增角色
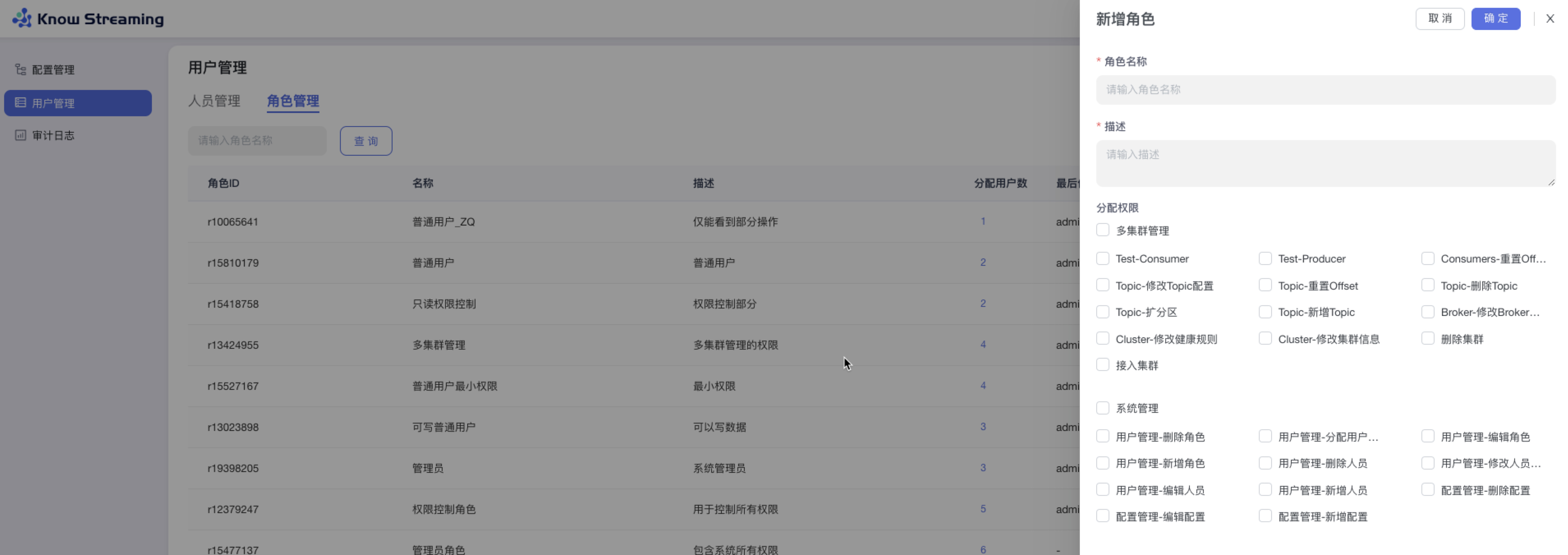
步骤 1:点击“系统管理”>“用户管理”>“角色管理”>“新增角色”
步骤 2:输入“角色名称”(角色名称只能由中英文大小写、数字、下划线_组成,长度限制在 3 ~ 128 字符)、“角色描述“(不能为空)、“分配权限“(至少需要分配一项权限),点击确认,新增角色成功添加到角色列表
5.4.2.11、审计日志
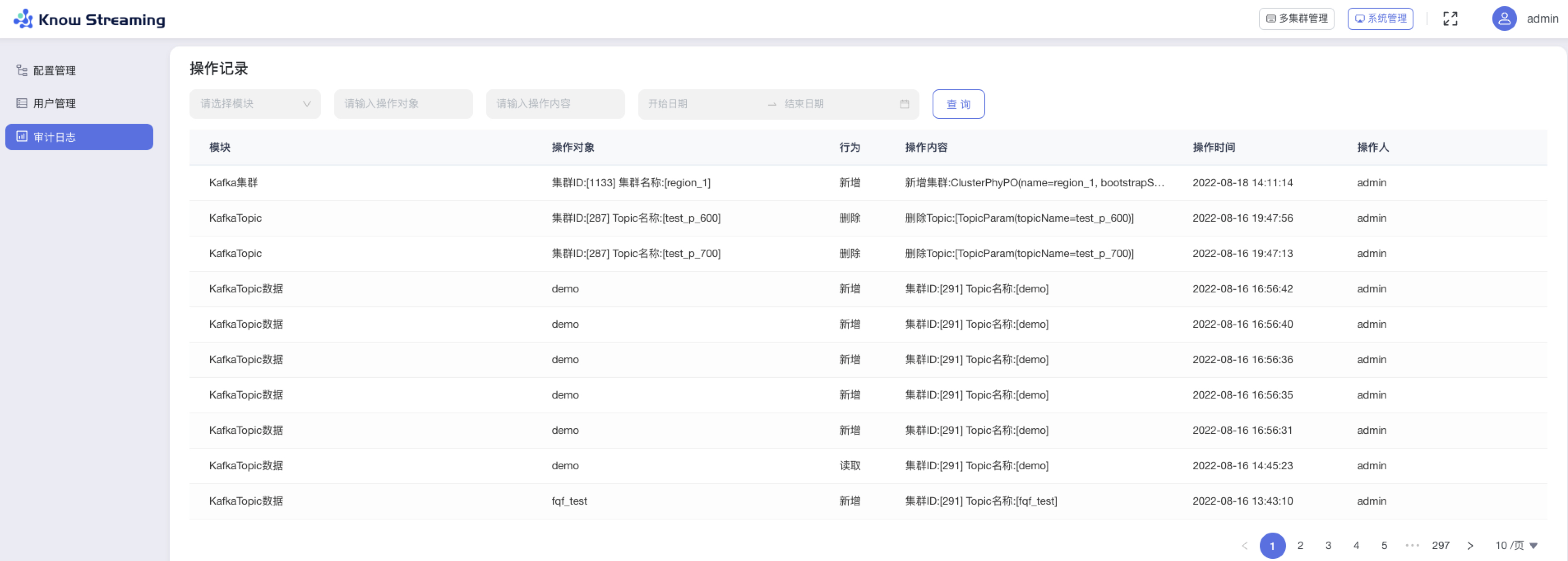
步骤 1:点击“系统管理”>“审计日志“
步骤 2:审计日志包含所有对于系统的操作记录,操作记录列表展示信息为下
- “模块”:操作对象所属的功能模块
- “操作对象”:具体哪一个集群、任务 ID、topic、broker、角色等
- “行为”:操作记录的行为,包含“新增”、“替换”、“读取”、“禁用”、“修改”、“删除”、“编辑”等
- “操作内容”:具体操作的内容是什么
- “操作时间”:操作发生的时间
- “操作人”:此项操作所属的用户
步骤 3:操作记录列表可以对“模块“、”操作对象“、“操作内容”、”操作时间“进行筛选
5.4.3、多集群管理
5.4.3.1、多集群列表
步骤 1:点击顶部导航栏“多集群管理”
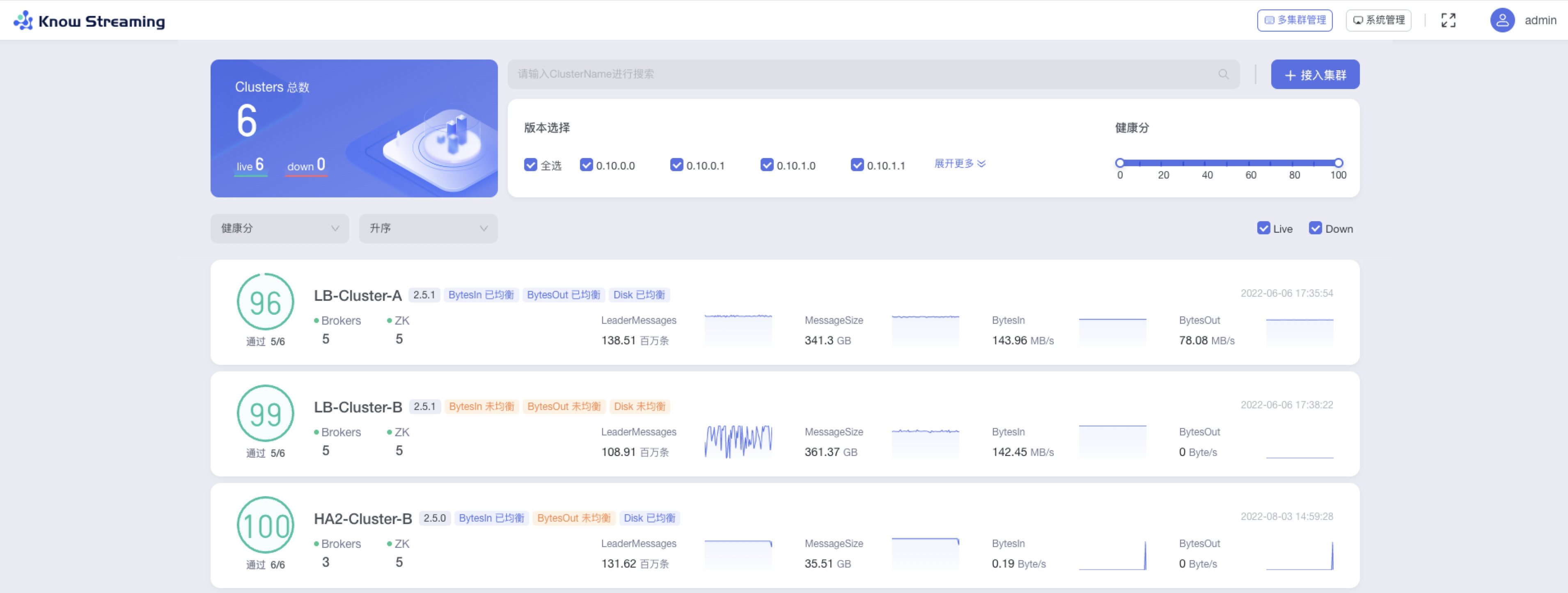
步骤 2:多集群管理页面包含的信息为:”集群信息总览“、“集群列表”、“列表筛选项”、“接入集群”
步骤 3:集群列表筛选项为
- 集群信息总览:cluster 总数、live 数、down 数
- 版本筛选:包含所有存在的集群版本
- 健康分筛选:筛选项为 0、10、20、30、40、50、60、70、80、90、100
- live、down 筛选:多选
- 下拉框筛选排序,选项维度为“接入时间”、“健康分“、”Messages“、”MessageSize“、”BytesIn“、”BytesOut“、”Brokers“;可对这些维度进行“升序”、“降序”排序
步骤 4:每个卡片代表一个集群,其所展示的集群概览信息包括“健康分及健康检查项通过数”、“broker 数量”、“ZK 数量”、“版本号”、“BytesIn 均衡状态”、“BytesOut 均衡状态”、“Disk 均衡状态”、”Messages“、“MessageSize”、“BytesIn”、“BytesOut”、“接入时间”
5.4.3.2、接入集群
步骤 1:点击“多集群管理”>“接入集群”
步骤 2:填写相关集群信息
- 集群名称:平台内不能重复
- Bootstrap Servers:输入 Bootstrap Servers 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)。
- Zookeeper:输入 zookeeper 地址,输入完成之后会进行连接测试,测试完成之后会给出测试结果连接成功 or 连接失败(以及失败的原因)
- Metrics 选填:JMX Port,输入 JMX 端口号;MaxConn,输入服务端最大允许的连接数
- Security:若有 JMX 账号密码,则输入账号密码
- Version:kafka 版本,如果没有匹配则可以选择相近版本
- 集群配置选填:用户创建 kafka 客户端进行信息获取的相关配置
5.4.3.3、删除集群
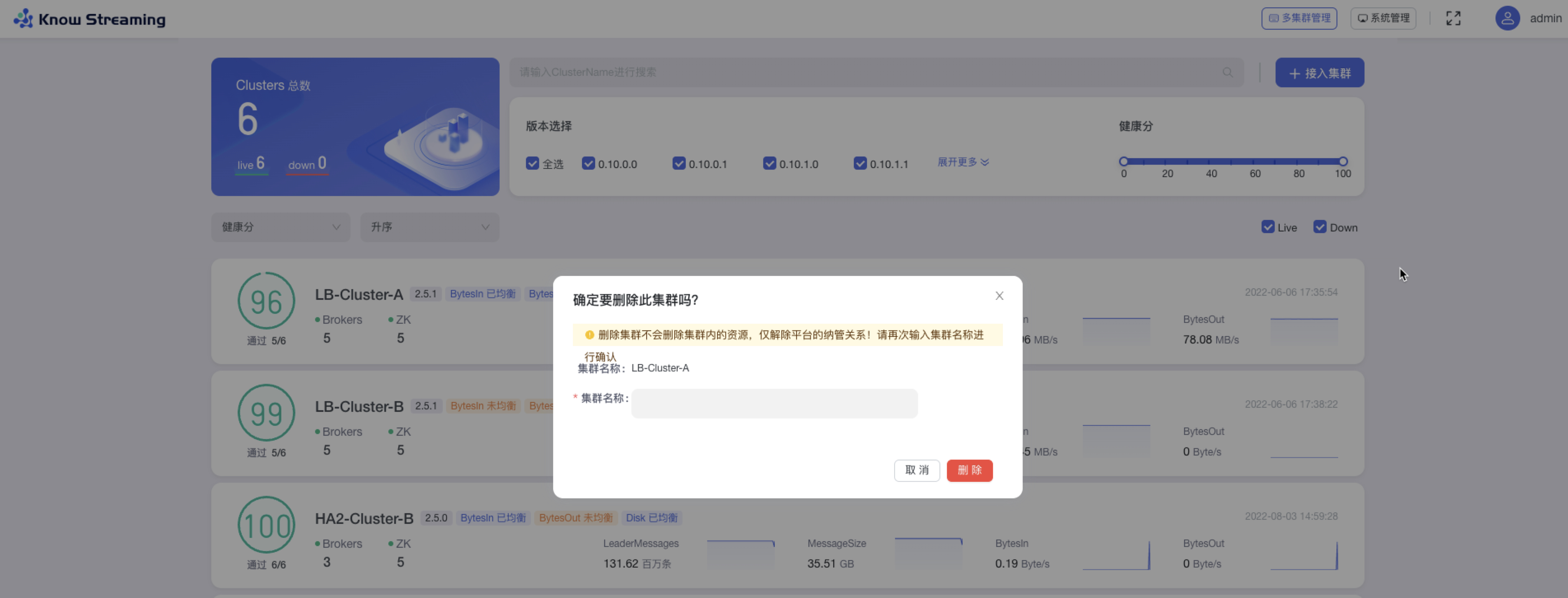
步骤 1:点击“多集群管理”>鼠标悬浮集群卡片>点击卡片右上角“删除 icon”>打开“删除弹窗”
步骤 2:在删除弹窗中的“集群名称”输入框,输入所要删除集群的集群名称,点击“删除”,成功删除集群,解除平台的纳管关系(集群资源不会删除)
5.4.4、Cluster 管理
5.4.4.1、Cluster Overview
步骤 1:点击“多集群管理”>“集群卡片”>进入单集群管理界面
步骤 2:左侧导航栏
- 一级导航:Cluster;二级导航:Overview、Load Rebalance
- 一级导航:Broker;二级导航:Overview、Brokers、Controller
- 一级导航:Topic;二级导航:Overview、Topics
- 一级导航:Consumer
- 一级导航:Testing;二级导航:Produce、Consume
- 一级导航:Security;二级导航:ACLs、Users
- 一级导航:Job
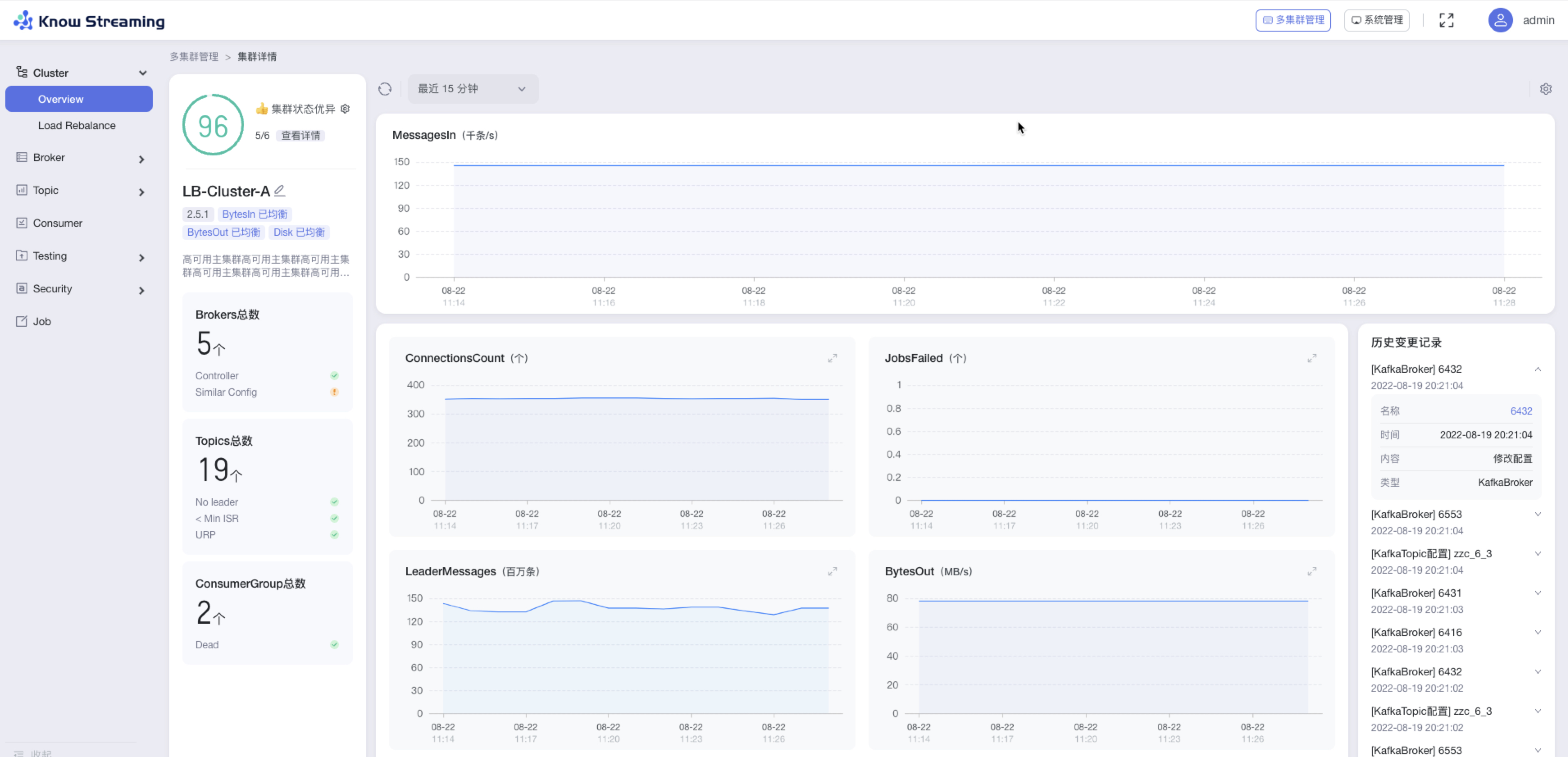
5.4.4.2、查看 Cluster 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”
步骤 2:cluster 概览信息包括以下内容
- 集群健康分,健康检查通过项
- Cluster 信息:包含名称、版本、均衡状态
- Broker 信息:Broker 总数、controller 信息、similar config 信息
- Topic 信息:Topic 总数、No Leader、<Min ISR、URP
- Consumer Group 信息:Consumer Group 总数、是否存在 Dead 情况
- 指标图表
- 历史变更记录:名称、时间、内容、类型
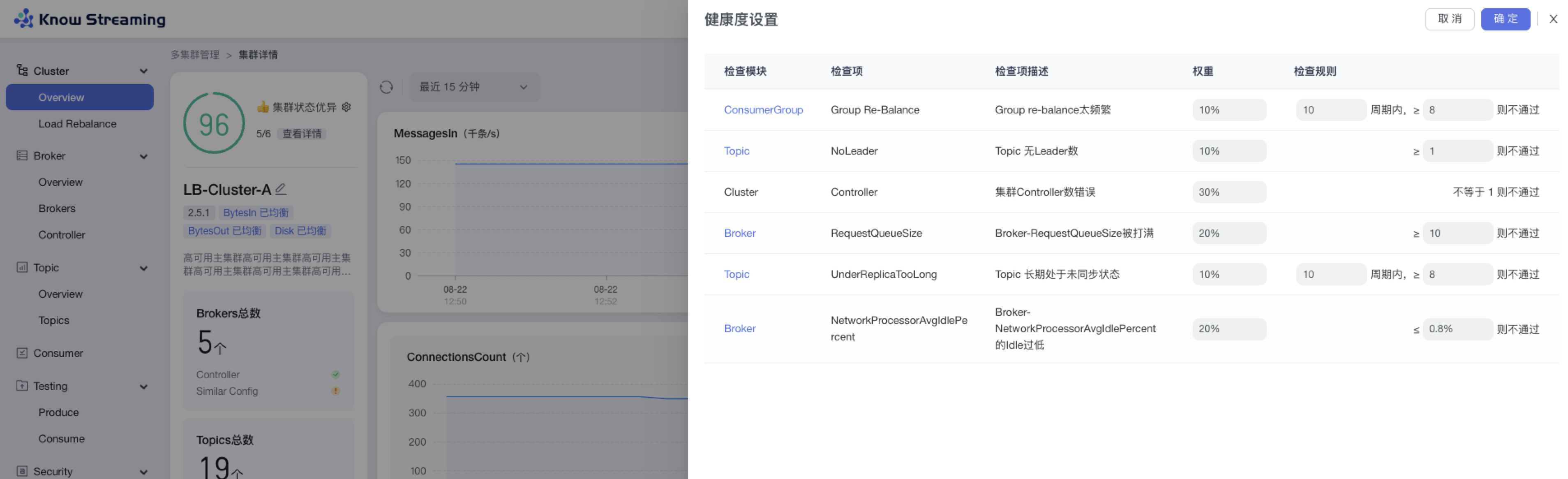
5.4.4.3、设置 Cluster 健康检查规则
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边 icon”>“健康度设置抽屉”
步骤 2:健康度设置抽屉展示出了检查项和其对应的权重,可以修改检查项的检查规则
步骤 3:检查规则可配置,分别为
- Cluster:集群 controller 数不等于 1(数字不可配置)不通过
- Broker:RequestQueueSize 大于等于 10(默认为 10,可配置数字)不通过
- Broker:NetworkProcessorAvgIdlePercent 的 Idle 小于等于 0.8%(默认为 0.8%,可配置数字)不通过
- Topic:无 leader 的 Topic 数量,大于等于 1(默认为 1,数字可配置)不通过
- Topic:Topic 在 10(默认为 10,数字可配置)个周期内 8(默认为 8,数字可配置)个周期内处于未同步的状态
- ConsumerGroup:Group 在 10(默认为 10,数字可配置)个周期内进行 8(默认为 8,数字可配置)次 re-balance 不通过
步骤 4:设置完成后,点击“确认”,健康检查规则设置成功
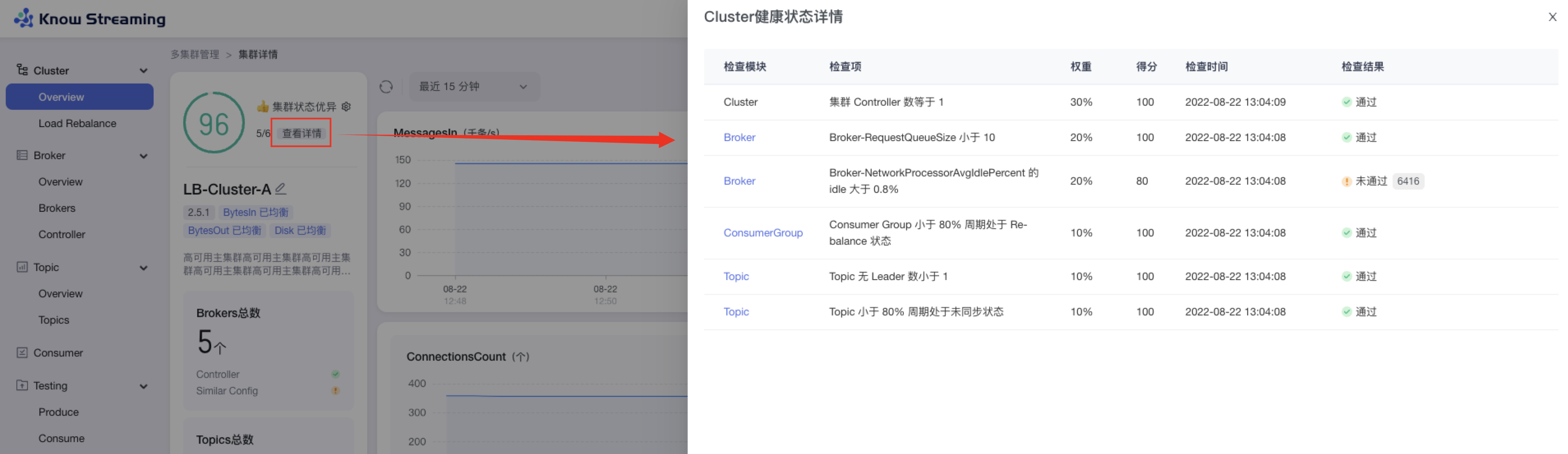
5.4.4.4、查看 Cluster 健康检查详情
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
步骤 2:健康检查详情抽屉展示信息为:“检查模块”、“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
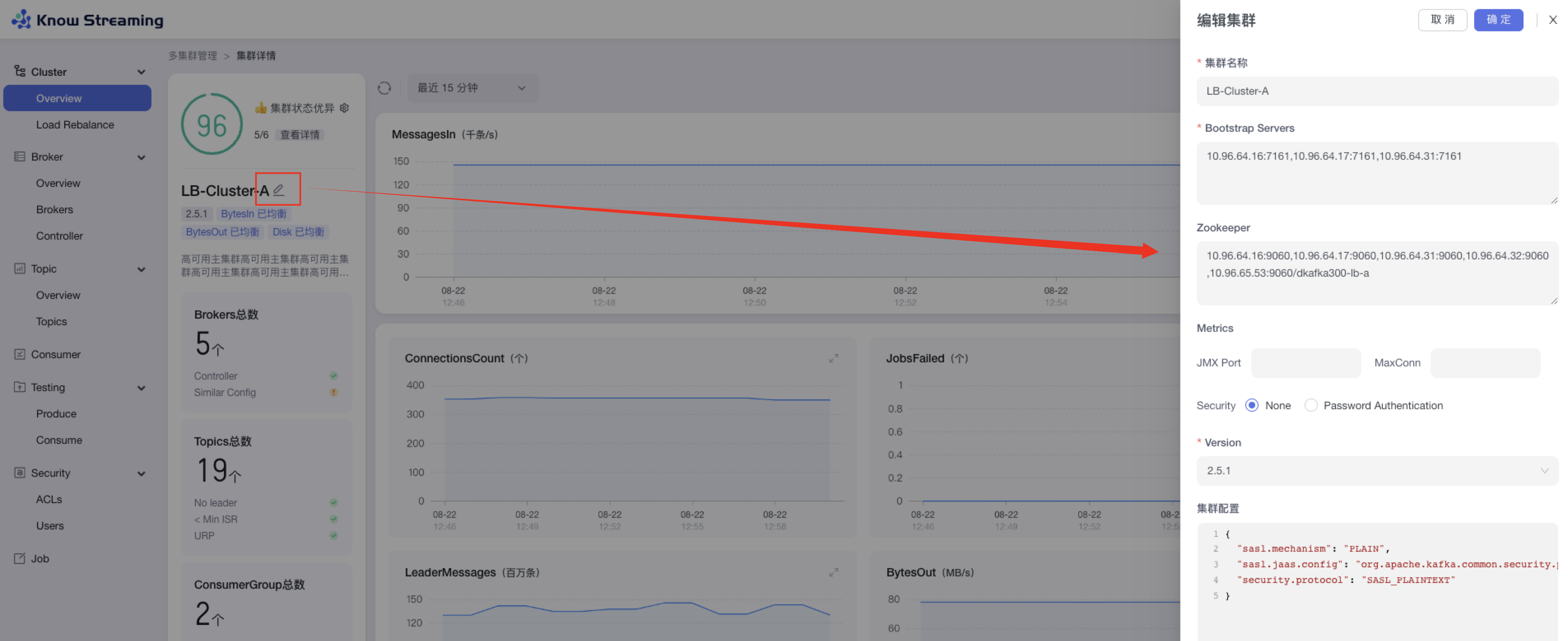
5.4.4.5、编辑 Cluster 信息
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“Cluster 名称旁边编辑 icon”>“编辑集群抽屉”
步骤 2:可编辑的信息包括“集群名称”、“Bootstrap Servers”、“Zookeeper”、“JMX Port”、“Maxconn(最大连接数)”、“Security(认证措施)”、“Version(版本号)”、“集群配置”、“集群描述”
步骤 3:点击“确定”,成功编辑集群信息
5.4.4.6、图表指标筛选
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“指标筛选 icon”>“指标筛选抽屉”
步骤 2:指标筛选抽屉展示信息为以下几类“Health”、“Cluster”、“Broker”、“Consumer”、“Security”、“Job”
步骤 3:默认勾选比较重要的指标进行展示。根据需要选中/取消选中相应指标,点击”确认“,指标筛选成功,展示的图表随之变化
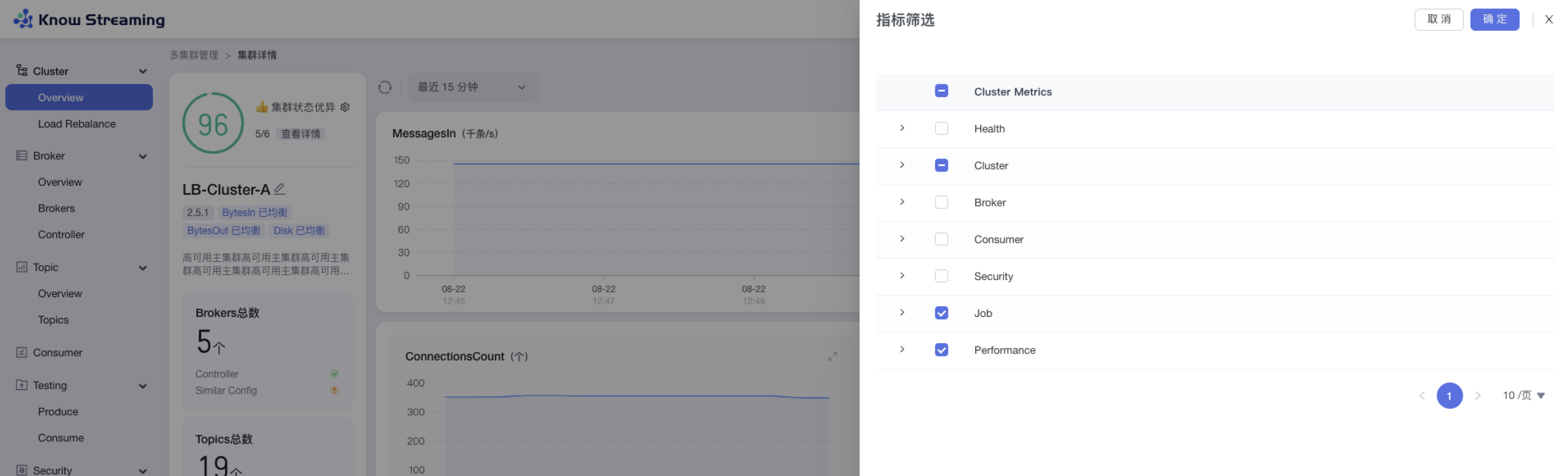
5.4.4.7、图表时间筛选
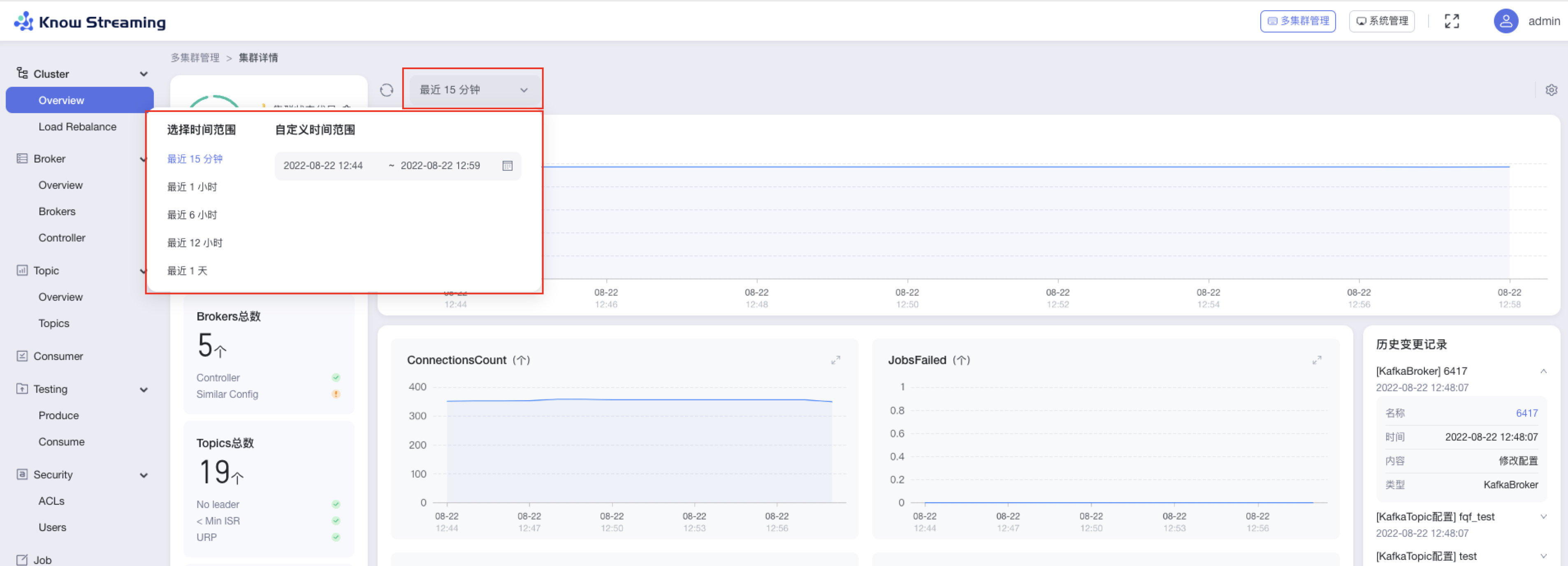
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“时间选择下拉框”>“时间选择弹窗”
步骤 2:选择时间“最近 15 分钟”、“最近 1 小时”、“最近 6 小时”、“最近 12 小时”、“最近 1 天”,也可以自定义时间段范围
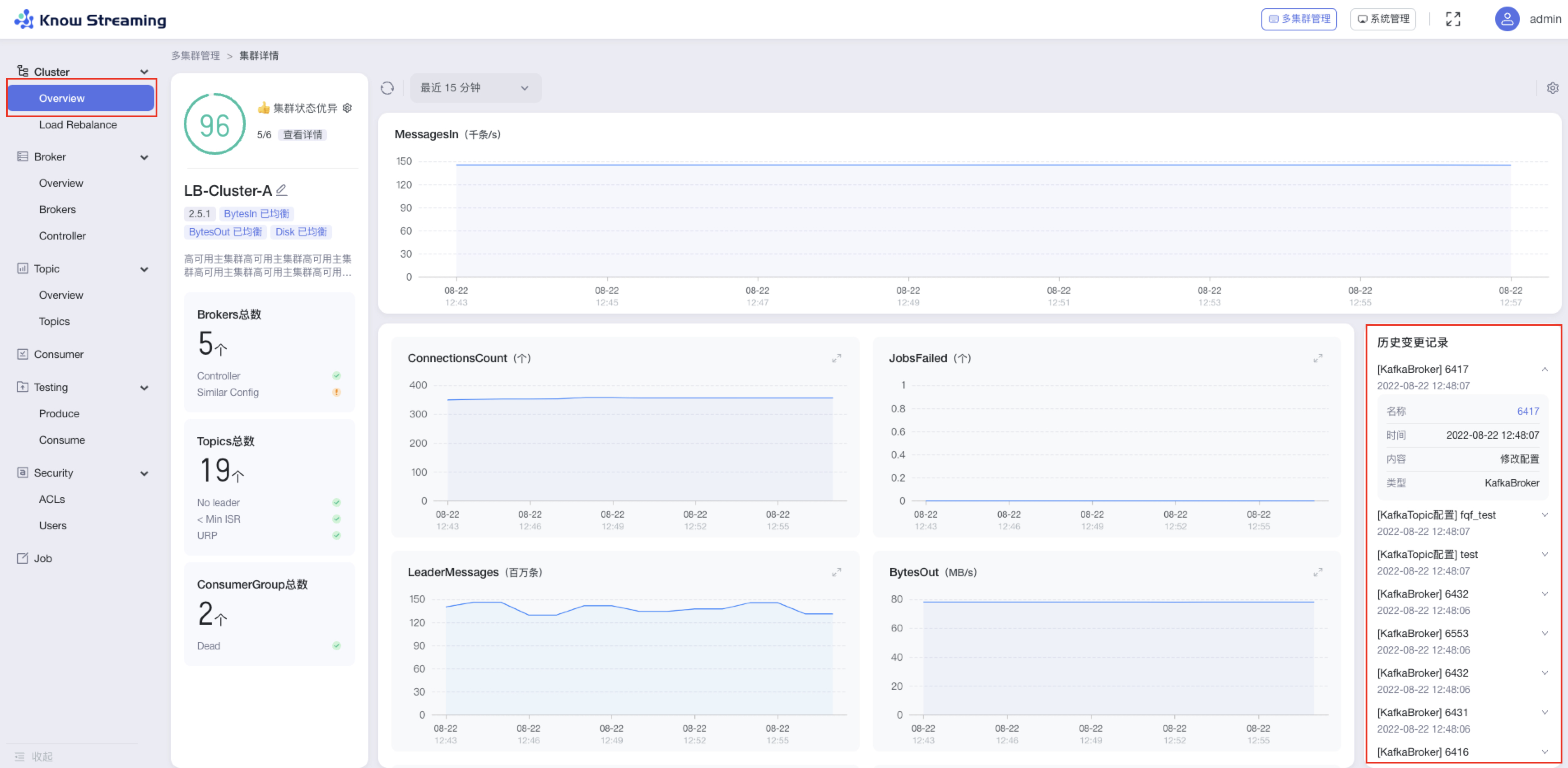
5.4.4.8、查看集群历史变更记录
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Overview”>“历史变更记录”区域
步骤 2:历史变更记录区域展示了历史的配置变更,每条记录可展开收起。包含“配置对象”、“变更时间”、“变更内容”、“配置类型”
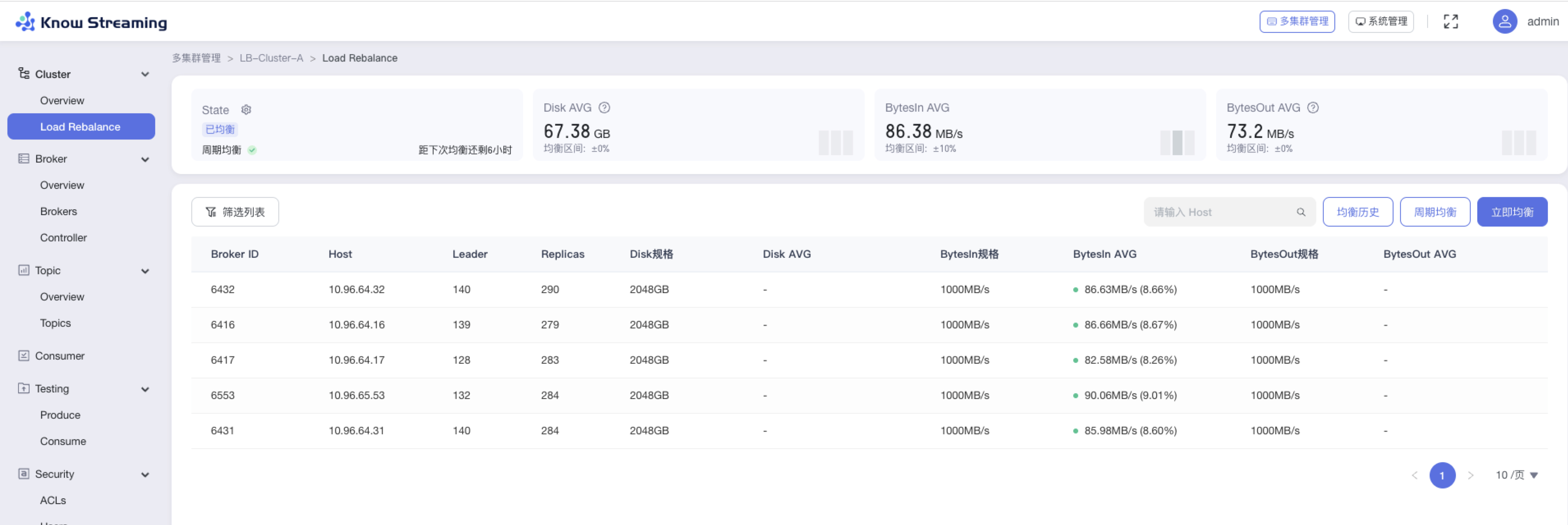
5.4.5、Load Rebalance(企业版)
5.4.5.1、查看 Load Rebalance 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”
步骤 2:Load Rebalance 概览信息包含“均衡状态卡片”、“Disk 信息卡片”、“BytesIn 信息卡片”、“BytesOut 信息卡片”、“Broker 均衡状态列表”
5.4.5.2、设置集群规格
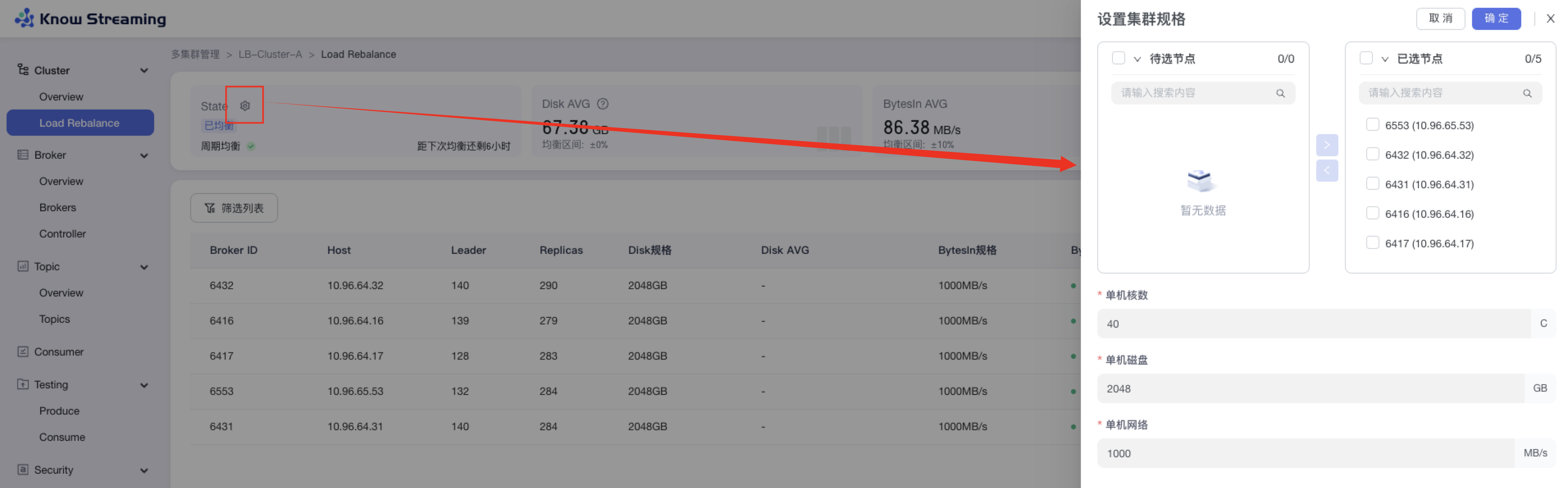
提供对集群的每个节点的 Disk、BytesIn、BytesOut 的规格进行设置的功能
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“State 卡片 icon“>”设置集群规格抽屉“
步骤 2:穿梭框左侧展示集群中的待选节点,穿梭框右侧展示已经选中的节点,选择自己所需设置规格的节点
步骤 3:设置“单机核数”、“单机磁盘”、“单机网络”,点击确定,完成设置
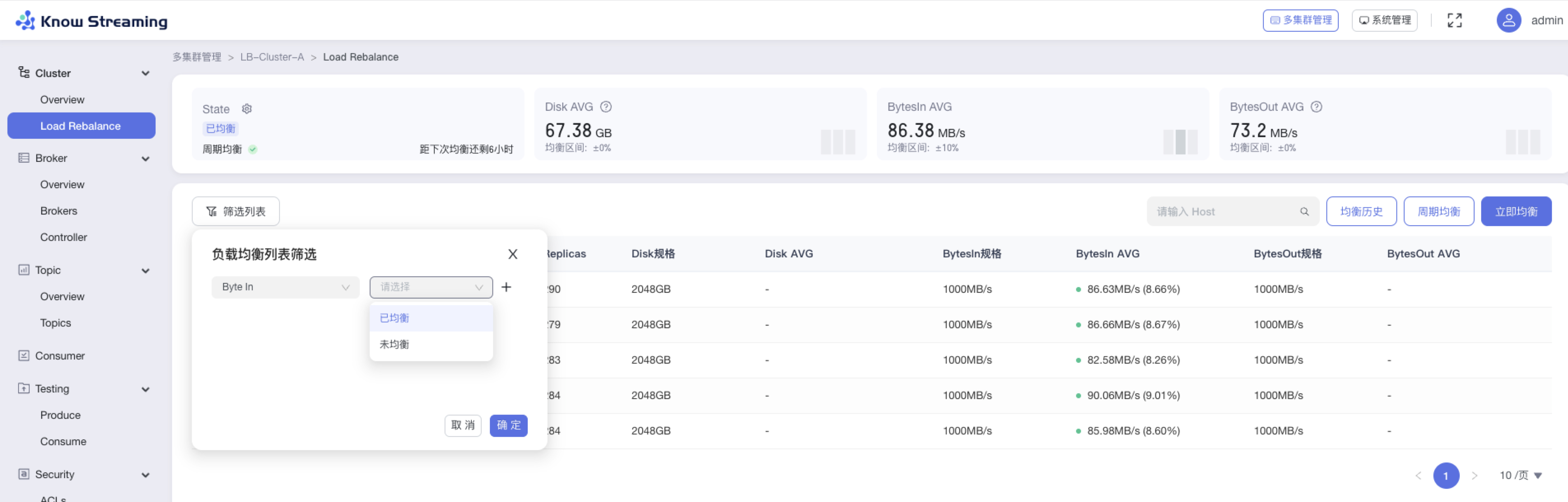
5.4.5.3、均衡状态列表筛选
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“筛选列表”按钮>筛选弹窗
步骤 2:可选择“Disk”、“BytesIn”、“BytesOut”三种维度,其各自对应“已均衡”、“未均衡”两种状态,可以组合进行筛选
步骤 3:点击“确认”,执行筛选操作
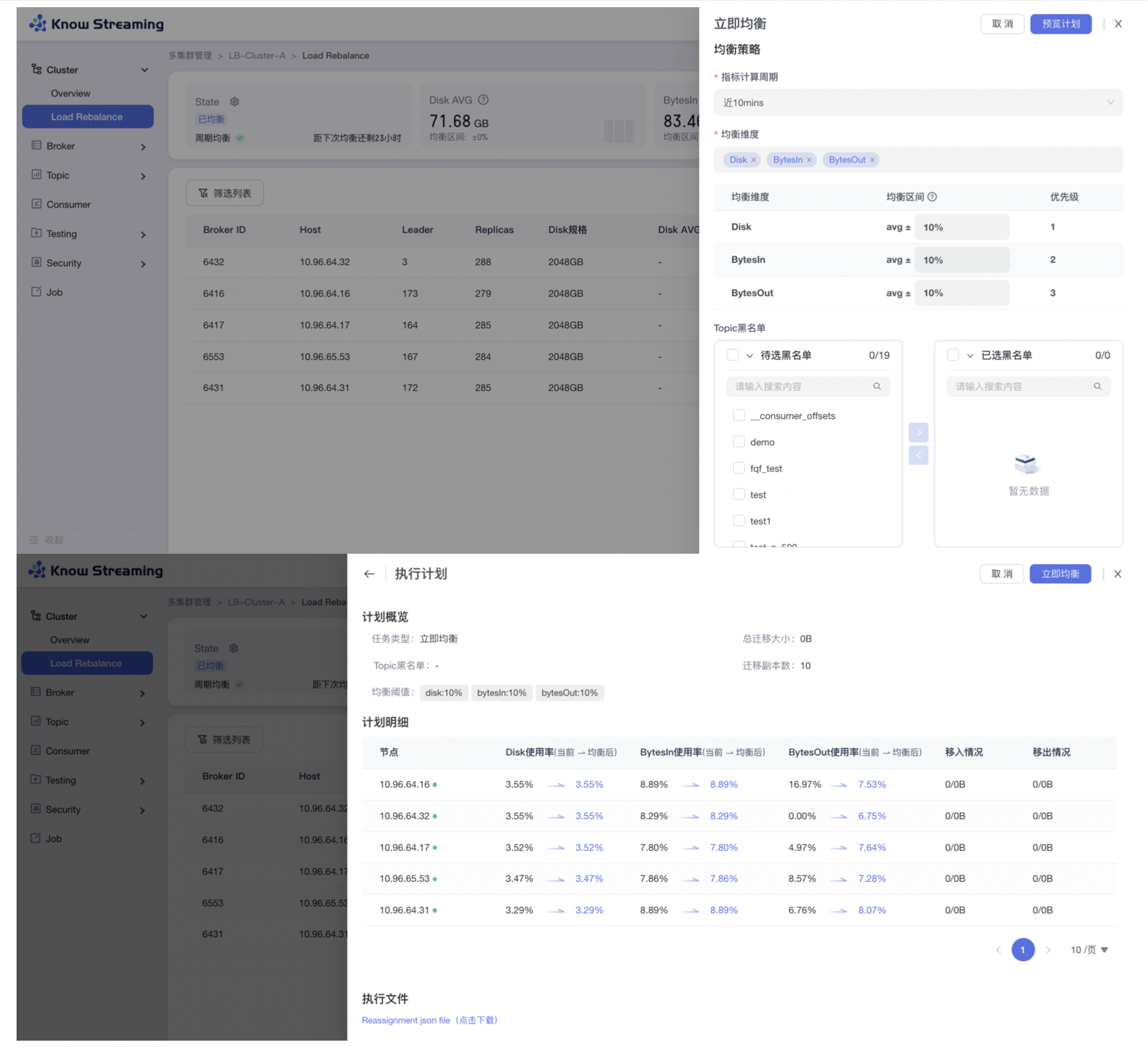
5.4.5.4、立即均衡
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“立即均衡”按钮>“立即均衡抽屉”
步骤 2:配置均衡策略
- 指标计算周期:默认近 10mins,可选择
- 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
步骤 3:配置运行参数
- 吞吐量优先:并行度 0(无限制), 策略是优先执行大小最大副本
- 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- 自定义:可以自由设置并行度和优先执行的副本策略
- 限流值:流量最大值,0-99999 自定义
步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
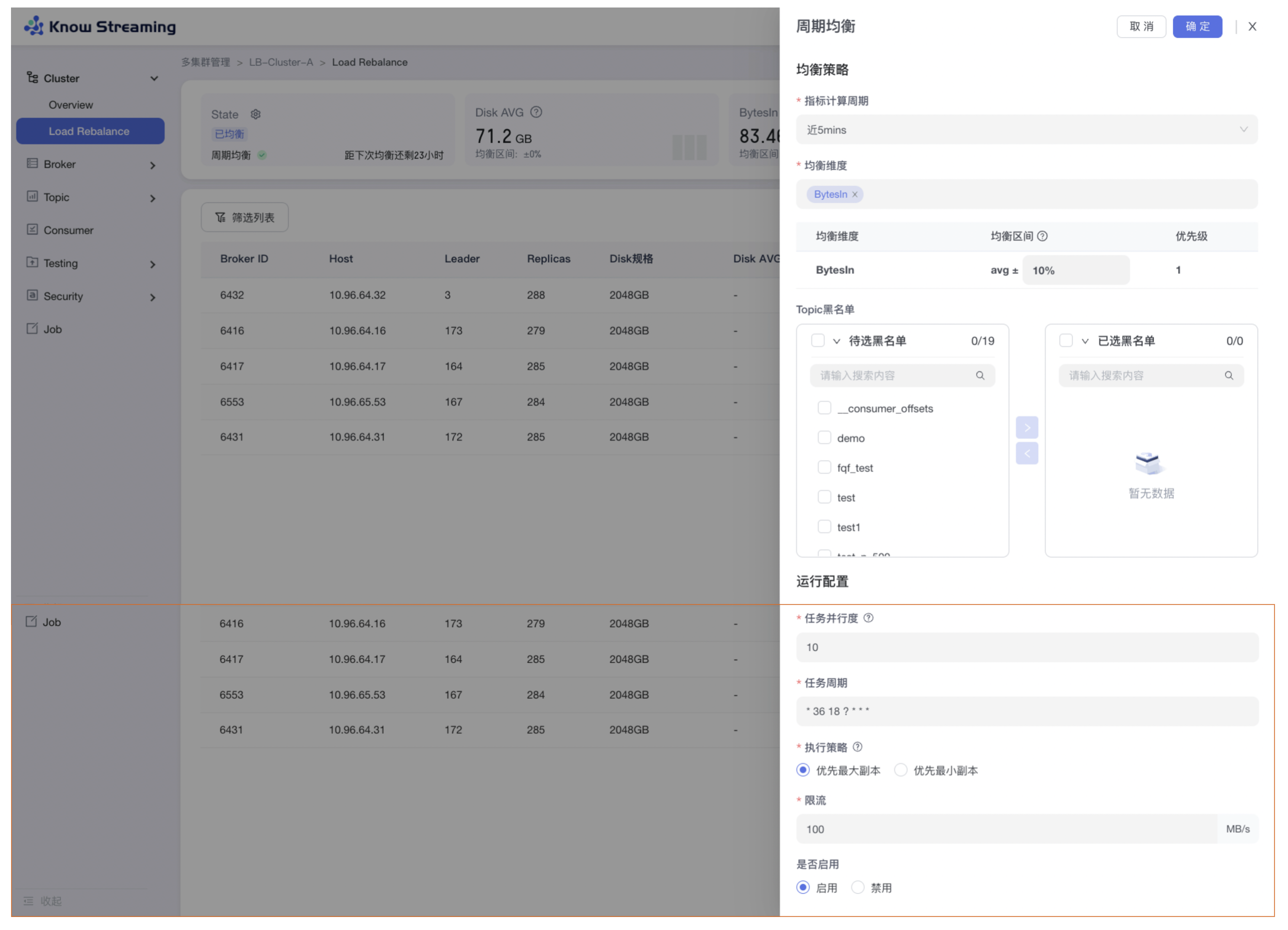
5.4.5.5、周期均衡
步骤 1:点击“多集群管理”>“集群卡片”>“Cluster”>“Load Rebalance”>“周期均衡”按钮>“周期均衡抽屉”
步骤 2:配置均衡策略
- 指标计算周期:默认近 10mins,可选择
- 均衡维度:默认 Disk、BytesIn、BytesOut,可选择
- 均衡区间:在表格内自定义配置均衡区间范围(单位:%,大于 0,小于 100)
- Topic 黑名单:选择 topic 黑名单。通过穿梭框(支持模糊选择)选出目标 topic(本次均衡,略过已选的 topic)
步骤 3:配置运行参数
- 任务并行度:每个节点同时迁移的副本数量
- 任务周期:时间选择器,自定义选择运行周期
- 稳定性优先: 并行度 1 ,策略是优先执行大小最小副本
- 自定义:可以自由设置并行度和优先执行的副本策略
- 限流值:流量最大值,0-99999 自定义
步骤 4:点击“预览计划”按钮,打开执行计划弹窗。可以看到计划概览信息、计划明细信息
步骤 5:点击“预览计划弹窗”的“执行文件”,可以下载 json 格式的执行文件
步骤 6:点击“预览计划弹窗”的“立即均衡”按钮,开始执行均衡任务
5.4.6、Broker
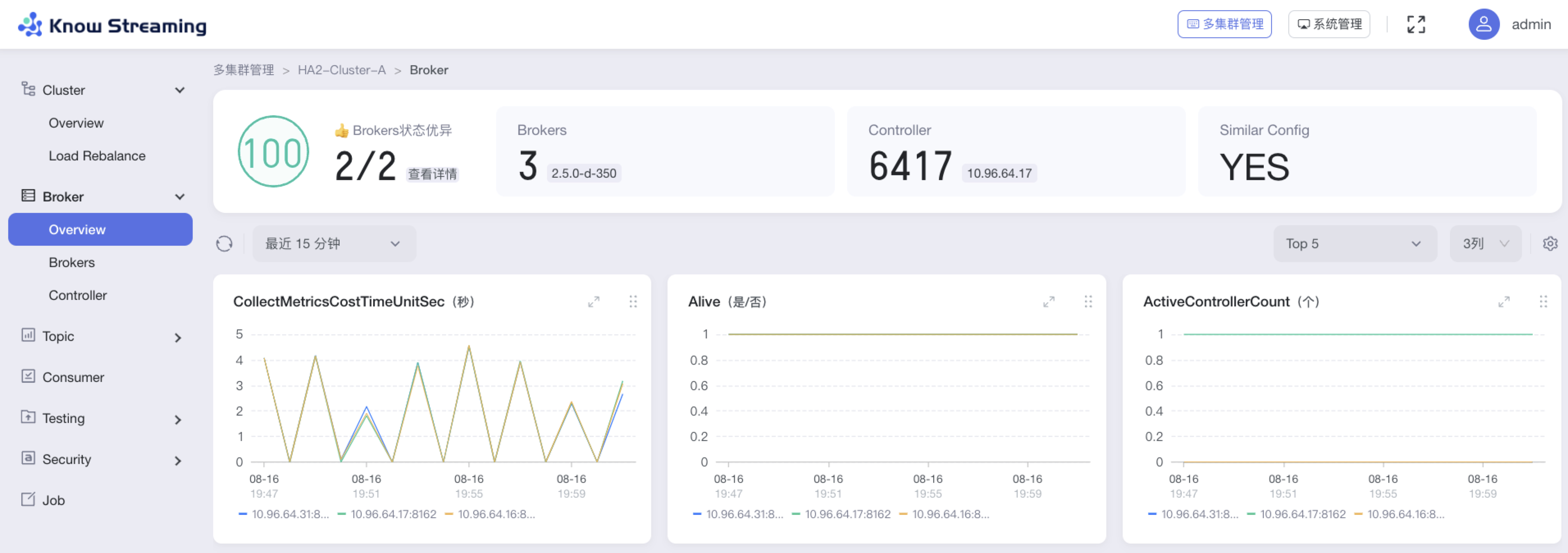
5.4.6.1、查看 Broker 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Overview”
步骤 2:Broker 概览信息包括以下内容
- 集群健康分,健康检查通过项
- Broker 信息:包含名称、版本、均衡状态
- Broker 信息:Broker 总数、controller 信息、similar config 信息
- Topic 信息:Topic 总数、No Leader、<Min ISR、URP
- Consumer Group 信息:Consumer Group 总数、是否存在 Dead 情况
- 指标图表
- 历史变更记录:名称、时间、内容、类型
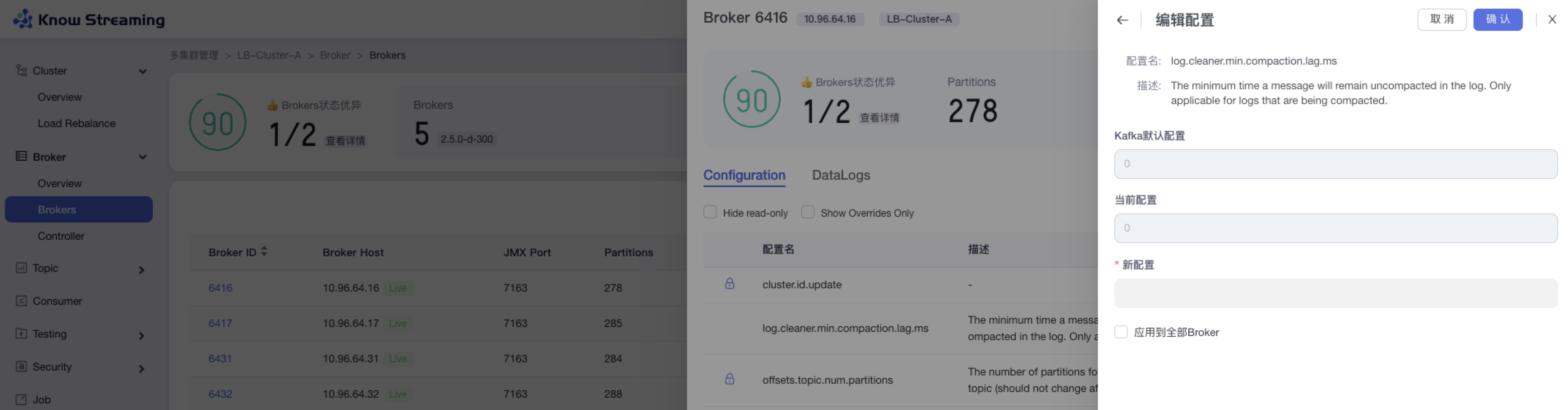
5.4.6.2、编辑 Broker 配置
步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Configuration”TAB>“编辑”按钮
步骤 2:输入配置项的新配置内容
步骤 3:(选填)点击“应用于全部 Broker”,将此配置项的修改应用于全部的 Broker
步骤 4:点击“确认”,Broker 配置修改成功
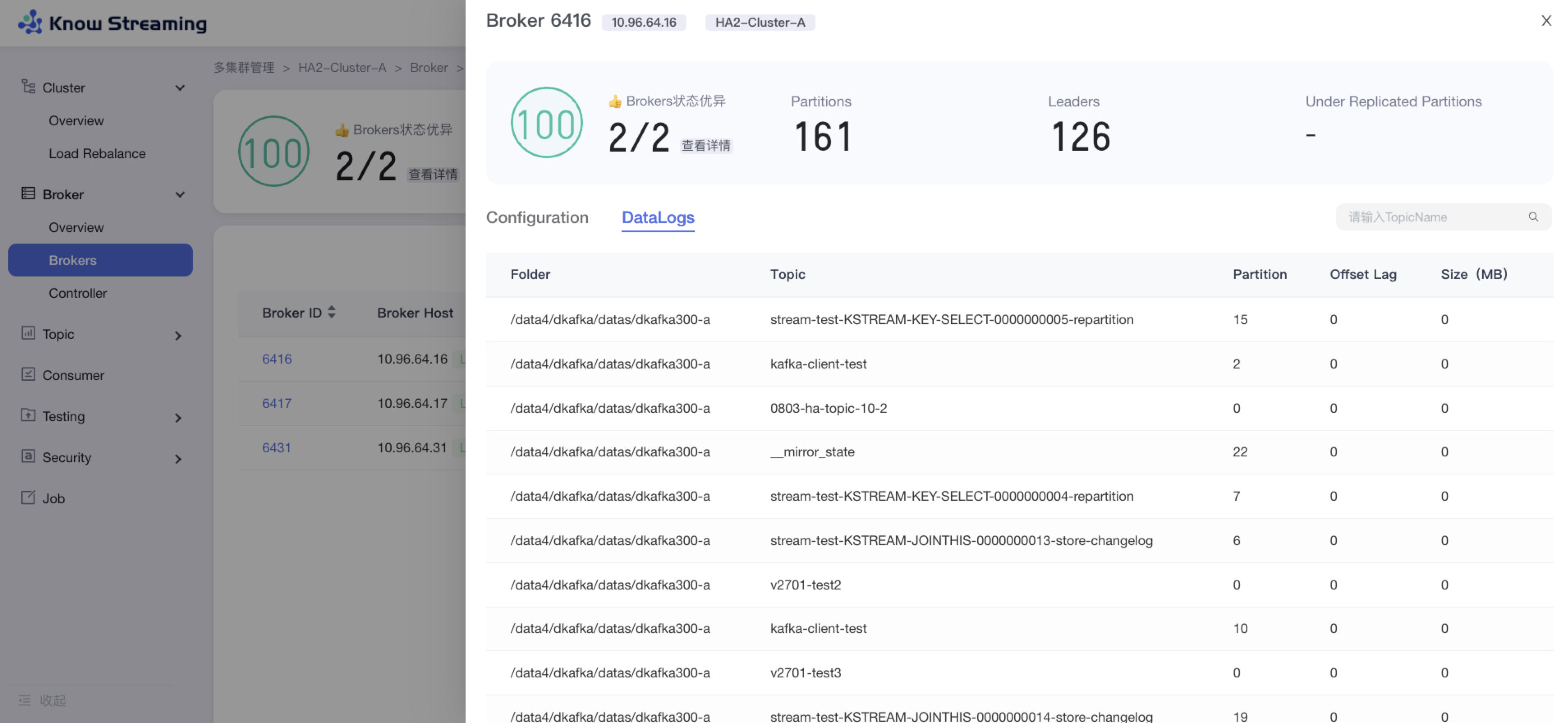
5.4.6.3、查看 Broker DataLogs
步骤 1:点击“多集群管理”>“集群卡片”>“Brokers”>“Broker ID”>“Data Logs”TAB>“编辑”按钮
步骤 2:Broker DataLogs 列表展示的信息为“Folder”、“topic”、“Partition”、“Offset Lag”、“Size”
步骤 3:输入框输入”Topic Name“可以筛选结果
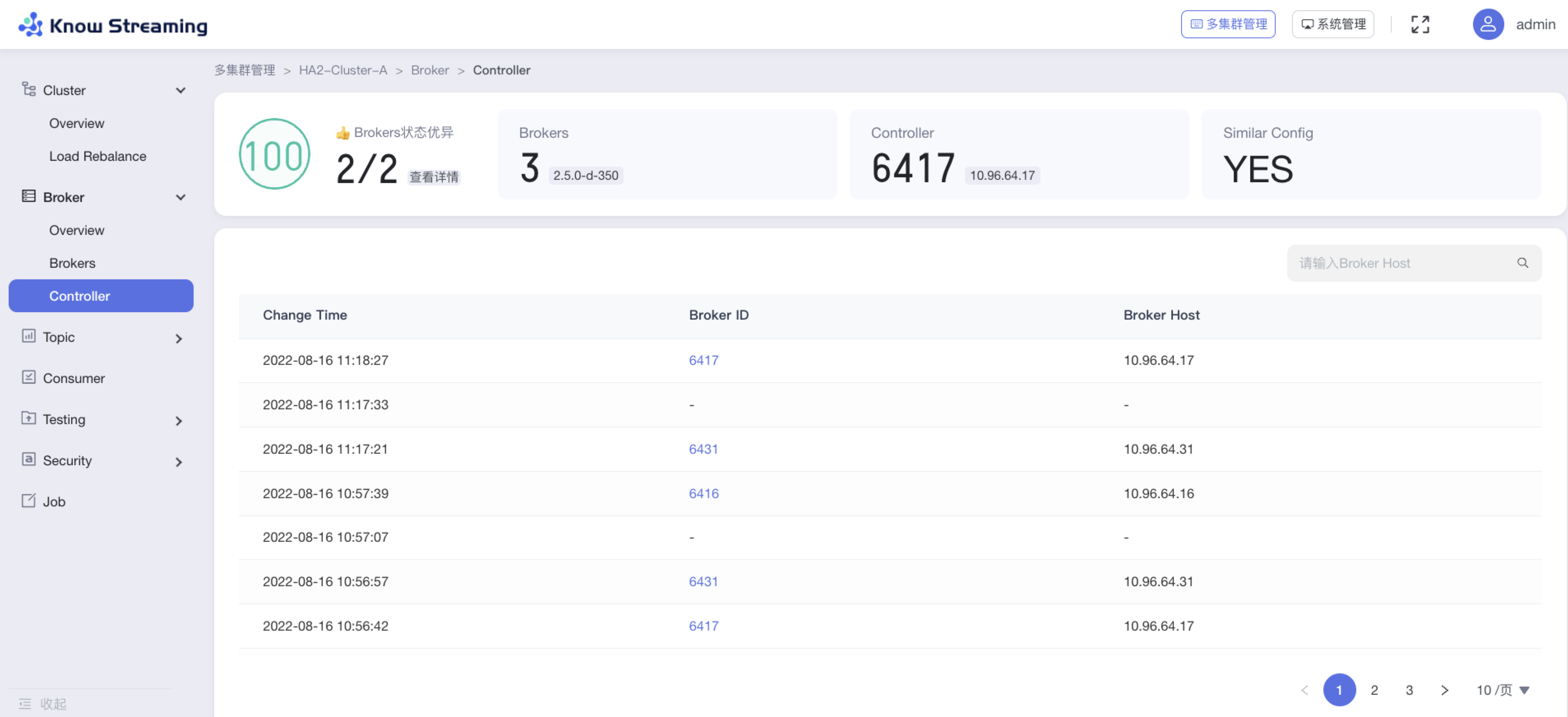
5.4.6.4、查看 Controller 列表
步骤 1:点击“多集群管理”>“集群卡片”>“Broker”>“Controller”
步骤 2:Controller 列表展示的信息为“Change Time”、“Broker ID”、“Broker Host”
步骤 3:输入框输入“Broker Host“可以筛选结果
步骤 4:点击 Broker ID 可以打开 Broker 详情,进行修改配置或者查看 DataLogs
5.4.7、Topic
5.4.7.1、查看 Topic 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”
步骤 2:Topic 概览信息包括以下内容
- 集群健康分,健康检查通过项
- Topics:Topic 总数
- Partitions:Partition 总数
- PartitionNoLeader:没有 leader 的 partition 个数
- < Min ISR:同步副本数小于 Min ISR
- =Min ISR:同步副本数等于 Min ISR
- Topic 指标图表
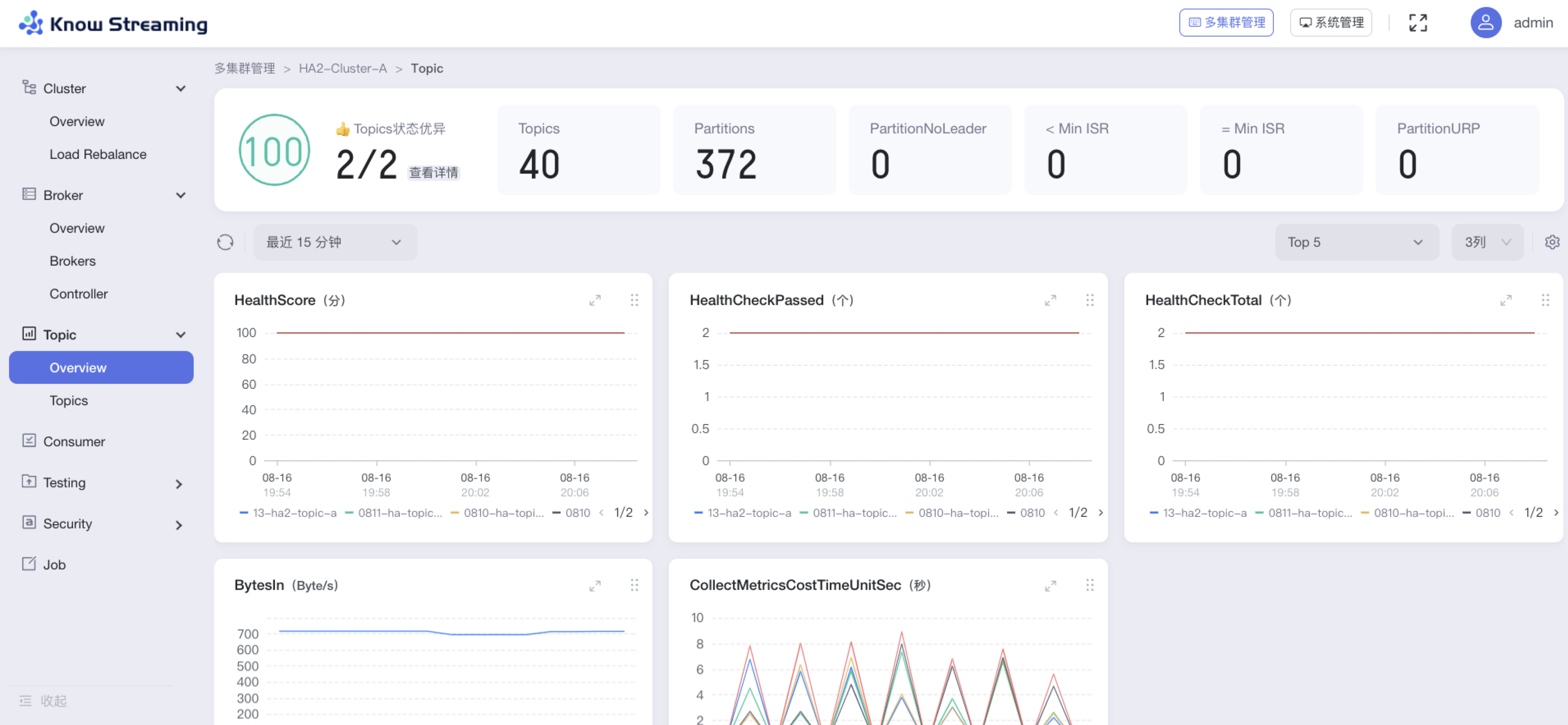
5.4.7.2、查看 Topic 健康检查详情
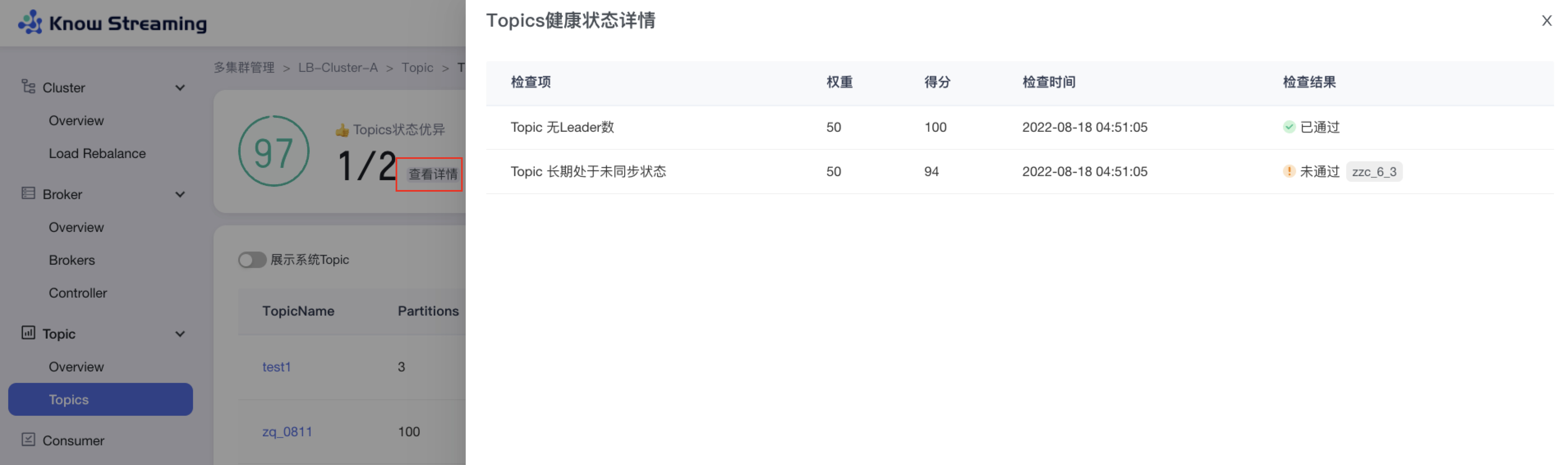
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Overview”>“集群健康状态旁边【查看详情】”>“健康检查详情抽屉”
步骤 2:健康检查详情抽屉展示信息为:“检查项”、“权重”、“得分”、“检查时间”、“检查结果是否通过”,若未通过会展示未通过的对象
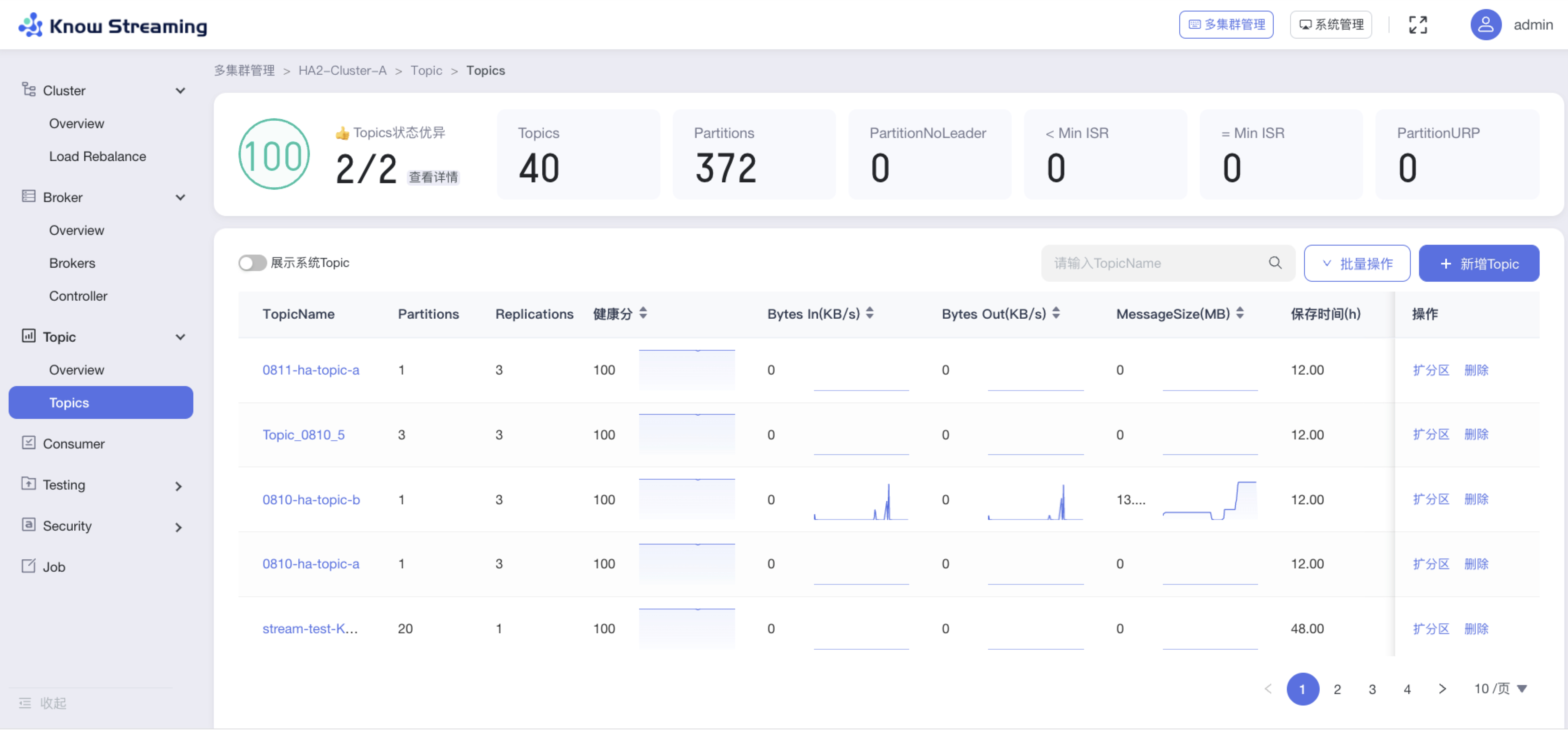
5.4.7.3、查看 Topic 列表
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”
步骤 2:Topic 列表展示内容为“TopicName”、“Partitions”、“Replications”、“健康分”、“BytesIn”、“BytesOut”、“MessageSize”、“保存时间”、“描述”、操作项”扩分区“、操作项”删除“
步骤 3:筛选框输入“TopicName”可以对列表进行筛选;点击“展示系统 Topic”开关,可以筛选系统 topic
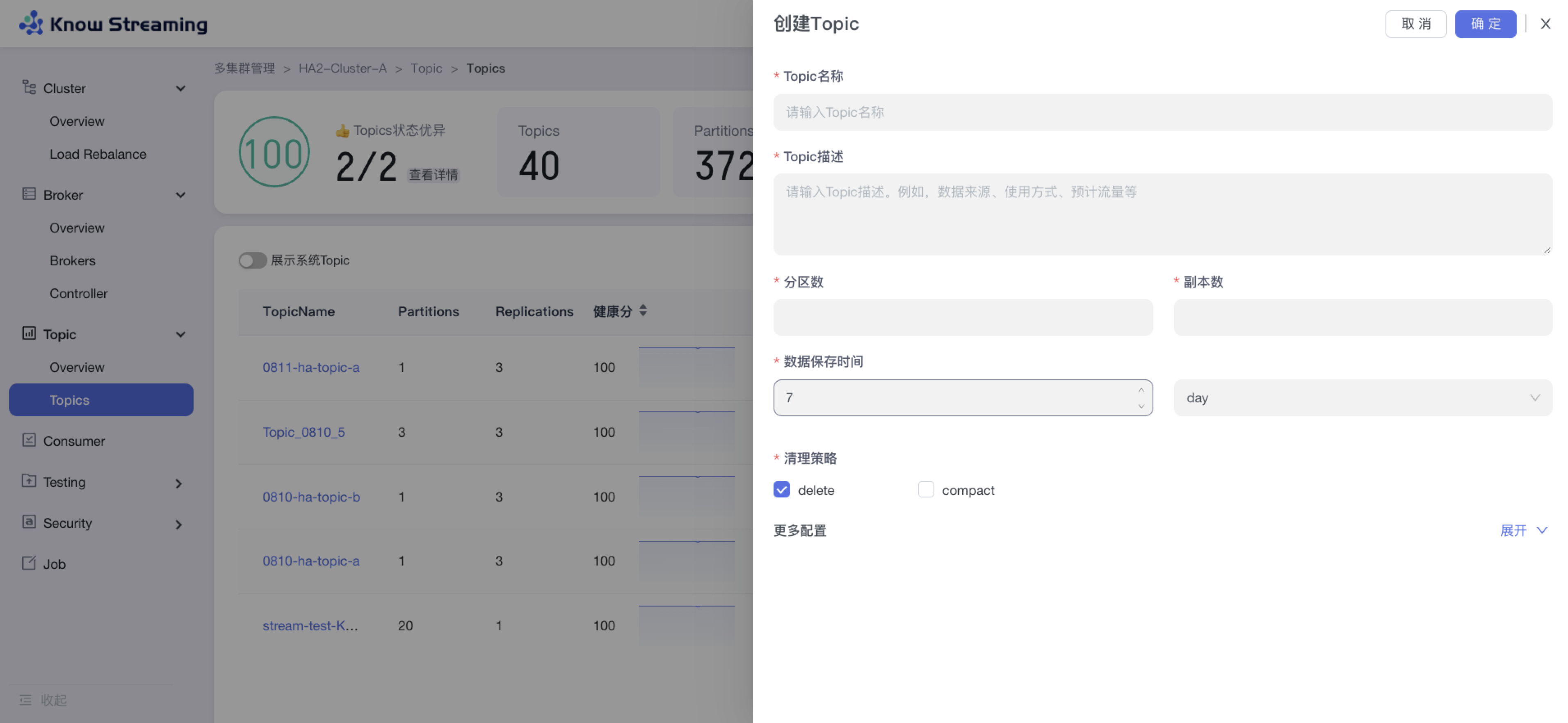
5.4.7.4、新增 Topic
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“新增 Topic”按钮>“创建 Topic“抽屉
步骤 2:输入“Topic 名称(不能重复)”、“Topic 描述”、“分区数”、“副本数”、“数据保存时间”、“清理策略(删除或压缩)”
步骤 3:展开“更多配置”可以打开高级配置选项,根据自己需要输入相应配置参数
步骤 4:点击“确定”,创建 Topic 完成
5.4.7.5、Topic 扩分区
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”扩分区“>“扩分区”抽屉
步骤 2:扩分区抽屉展示内容为“流量的趋势图”、“当前分区数及支持的最低消息写入速率”、“扩分区后支持的最低消息写入速率”
步骤 3:输入所需的分区总数,自动计算出扩分区后支持的最低消息写入速率
步骤 4:点击确定,扩分区完成
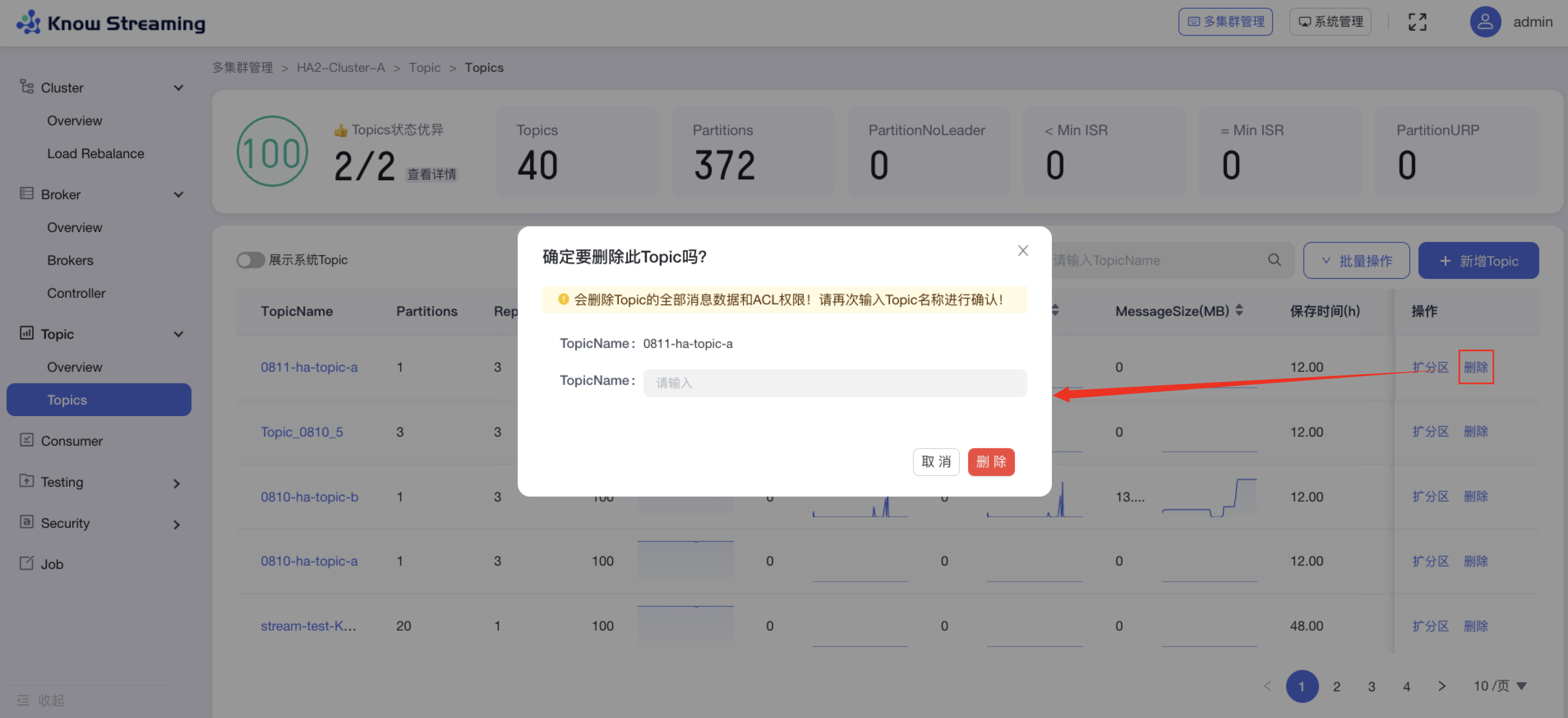
5.4.7.6、删除 Topic
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“Topic 列表“>操作项”删除“>“删除 Topic”弹窗
步骤 2:输入“TopicName”进行二次确认
步骤 3:点击“删除”,删除 Topic 完成
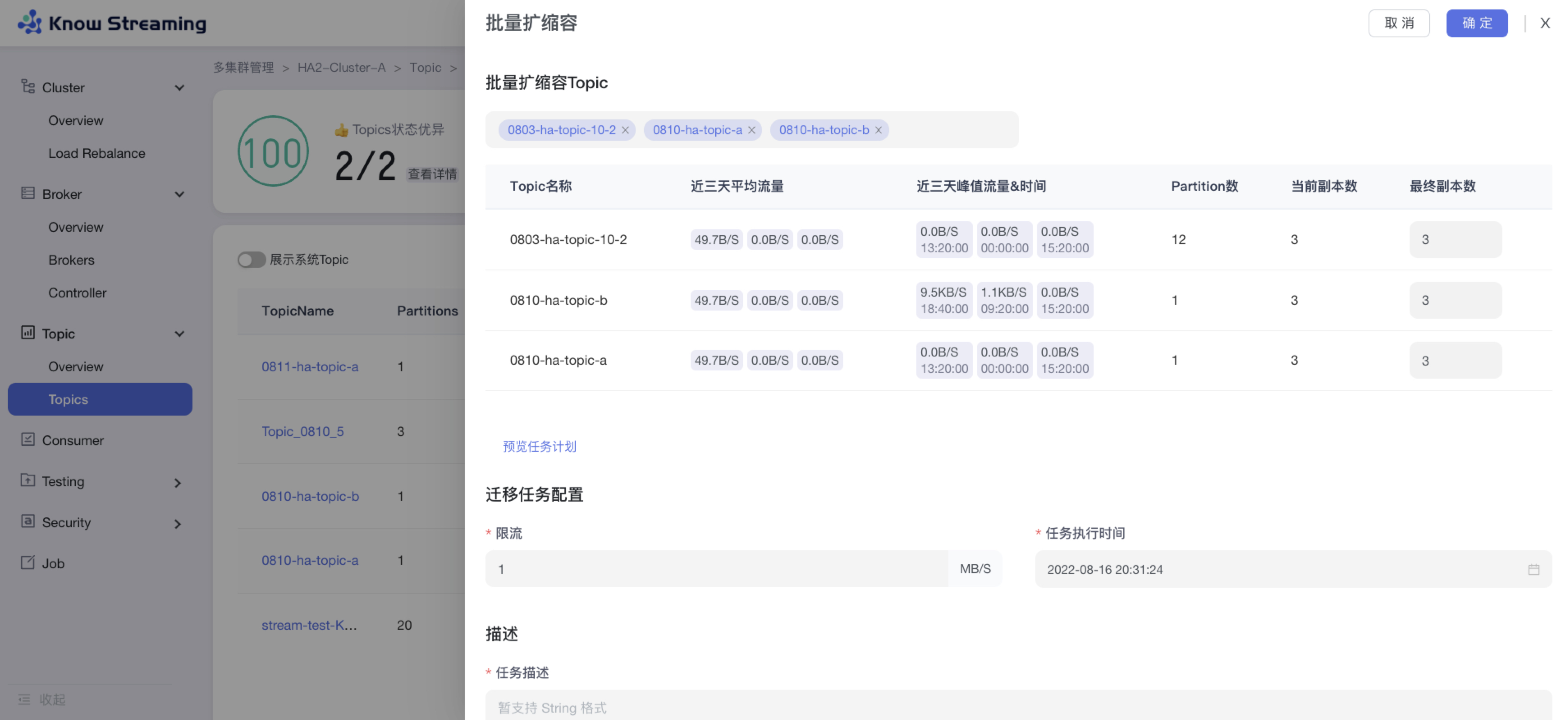
5.4.7.7、Topic 批量扩缩副本
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量扩缩副本“>“批量扩缩容”抽屉
步骤 2:选择所需要进行扩缩容的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
步骤 3:Topic 列表展示 Topic“近三天平均流量”、“近三天峰值流量及时间”、“Partition 数”、”当前副本数“、“新副本数”
步骤 4:扩容时,选择目标节点,新增的副本会在选择的目标节点上;缩容时不需要选择目标节点,自动删除最后一个(或几个)副本
步骤 5:输入迁移任务配置参数,包含限流值和任务执行时间
步骤 6:输入任务描述
步骤 7:点击“确定”,执行 Topic 扩缩容任务
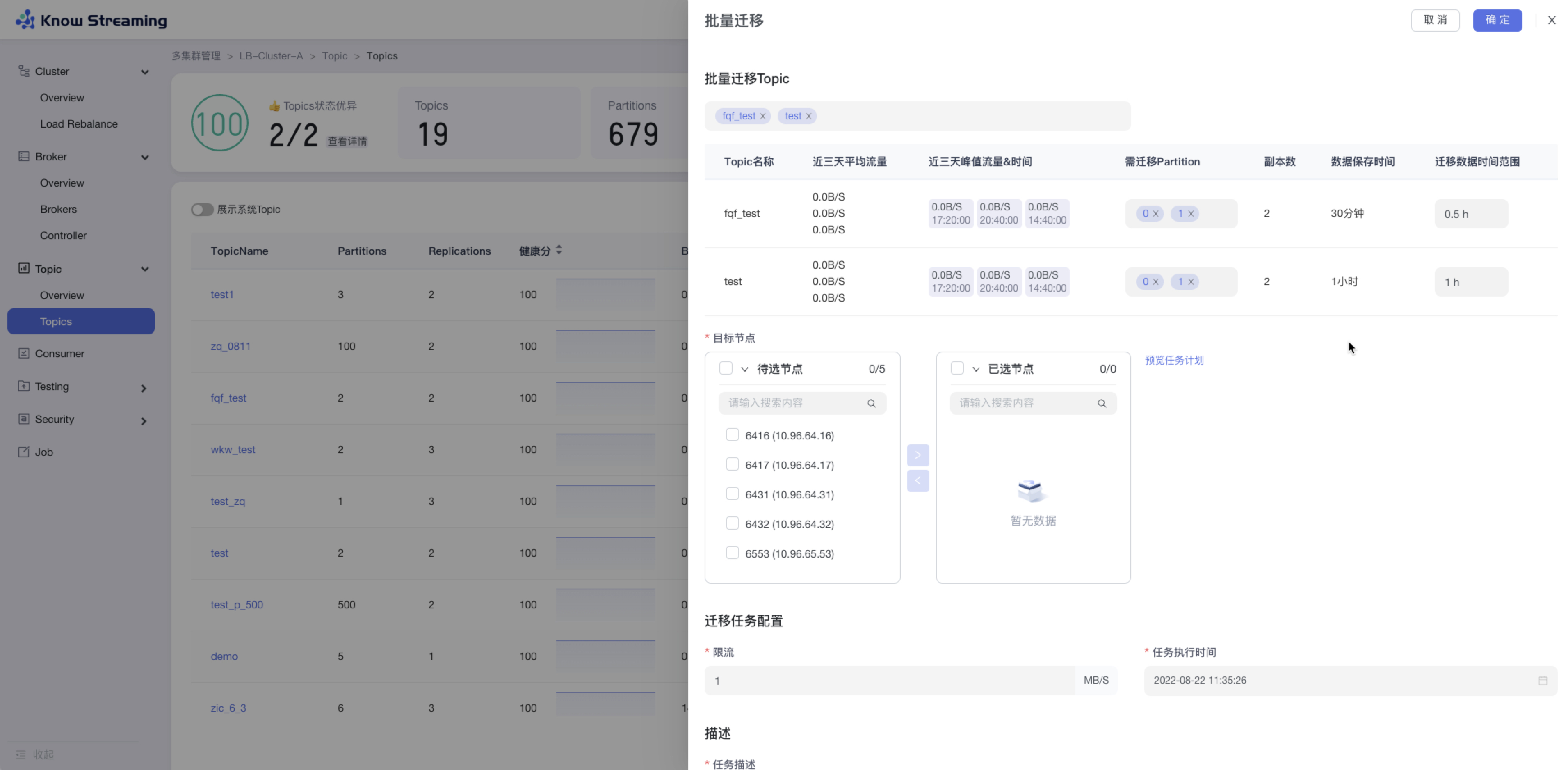
5.4.7.8、Topic 批量迁移
步骤 1:点击“多集群管理”>“集群卡片”>“Topic”>“Topics”>“批量操作下拉“>“批量迁移“>“批量迁移”抽屉
步骤 2:选择所需要进行迁移的 Topic,可多选,所选择的 Topic 出现在下方 Topic 列表中
步骤 3:选择所需要迁移的 partition 和迁移数据的时间范围
步骤 4:选择目标节点(节点数必须不小于最大副本数)
步骤 5:点击“预览任务计划”,打开“任务计划”二次抽屉,可对每个 partition 的目标 Broker ID 进行编辑,目标 broker 应该等于副本数
步骤 6:输入迁移任务配置参数,包含限流值和任务执行时间
步骤 7:输入任务描述
步骤 8:点击“确定”,执行 Topic 迁移任务
5.4.8、Consumer
5.4.8.1、Consumer Overview
步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”
步骤 2:Consumer 概览信息包括以下内容
- 集群健康分,健康检查通过项
- Groups:Consumer Group 总数
- GroupsActives:活跃的 Group 总数
- GroupsEmptys:Empty 的 Group 总数
- GroupRebalance:进行 Rebalance 的 Group 总数
- GroupDeads:Dead 的 Group 总数
- Consumer Group 列表
步骤 3:输入“Consumer Group”、“Topic Name‘,可对列表进行筛选
步骤 4:点击列表“Consumer Group”名称,可以查看 Comsuer Group 详情
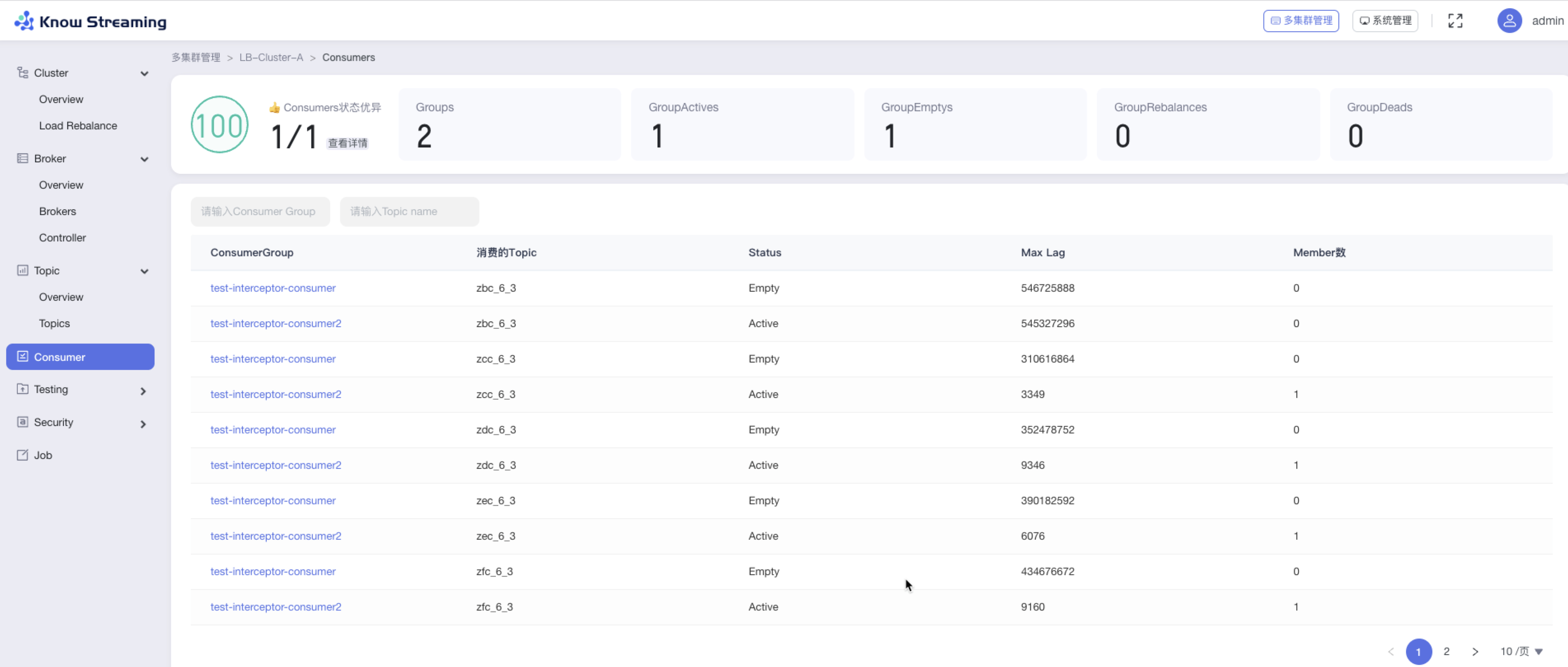
5.4.8.2、查看 Consumer 列表
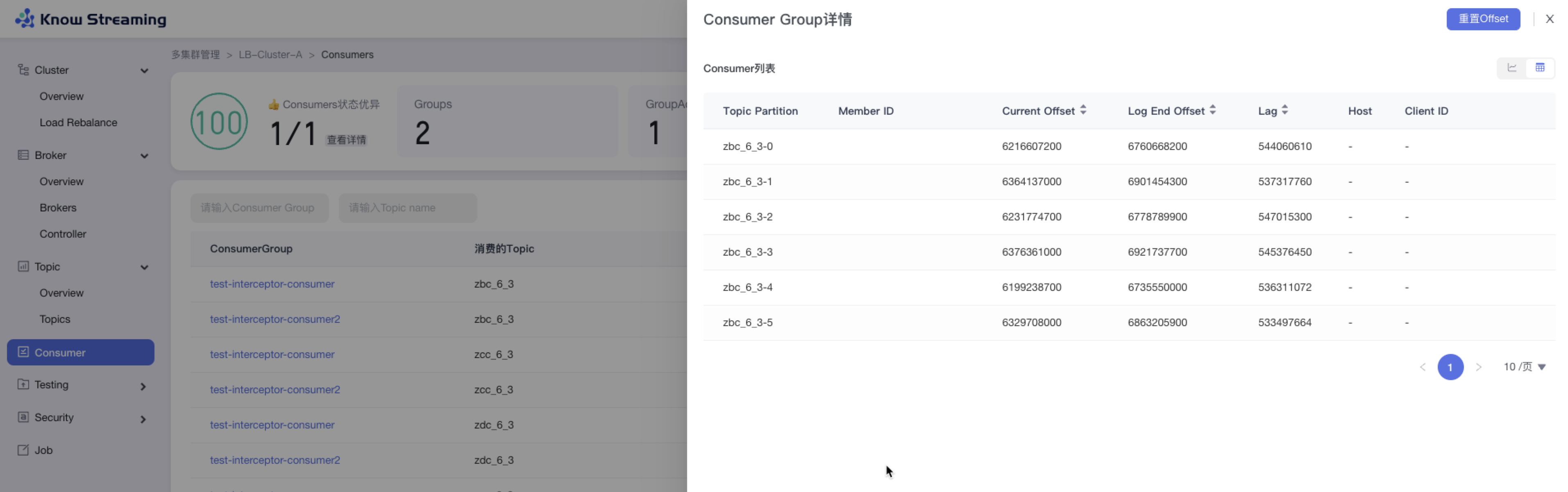
步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉
步骤 2:Consumer Group 详情有列表视图和图表视图
步骤 3:列表视图展示信息为 Consumer 列表,包含”Topic Partition“、”Member ID“、”Current Offset“、“Log End Offset”、”Lag“、”Host“、”Client ID“
5.4.8.3、重置 Offset
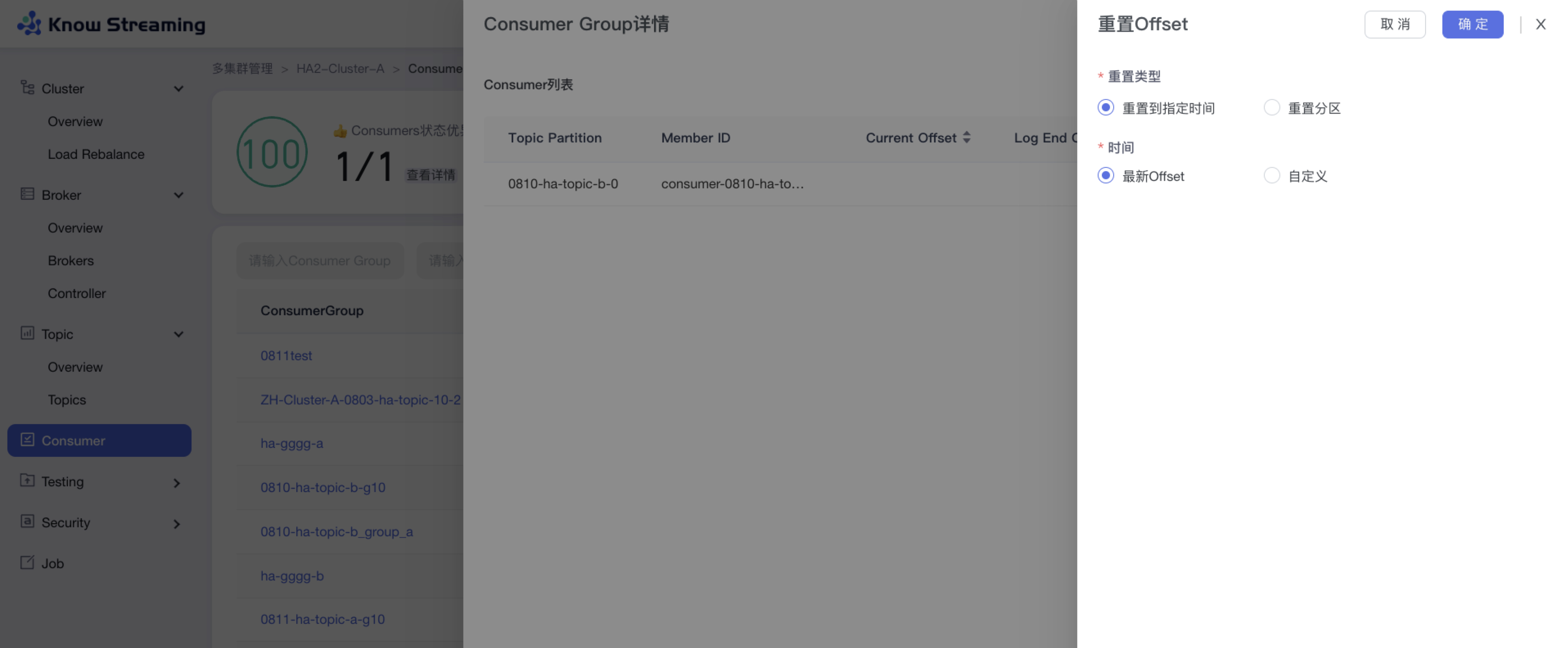
步骤 1:点击“多集群管理”>“集群卡片”>“Consumer”>“Consumer Group”名称>“Consumer Group 详情”抽屉>“重置 Offset”按钮>“重置 Offset”抽屉
步骤 2:选择重置 Offset 的类型,可“重置到指定时间”或“重置分区”
步骤 3:重置到指定时间,可选择“最新 Offset”或“自定义时间”
步骤 4:重置分区,可选择 partition 和其重置的 offset
步骤 5:点击“确认”,重置 Offset 开始执行
5.4.9、Testing(企业版)
5.4.9.1、生产测试
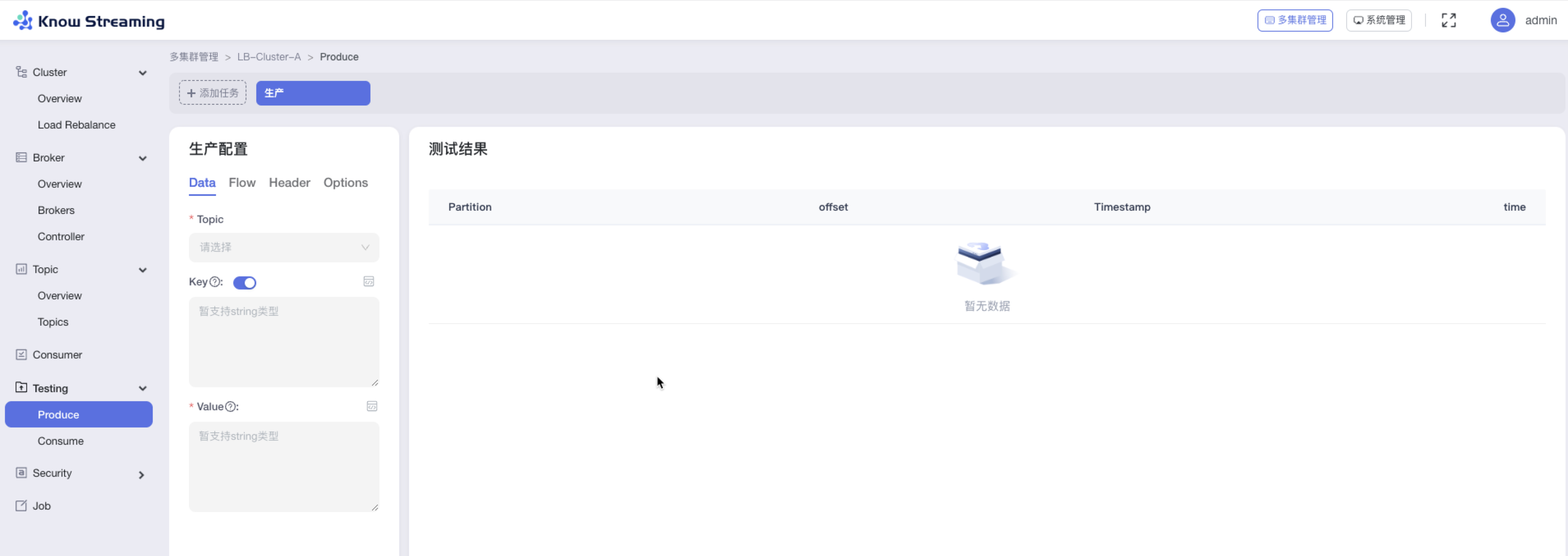
步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Produce”
步骤 2:生产配置
- Data:选择数据写入的 topic,输入写入数据的 key(暂只支持 string 格式),输入写入数据的 value(暂只支持 string 格式)。其中 key 和 value 可以随机生成
- Flow:输入单次发送的消息数量,默认为 1,可以手动修改。选择手动生产模式,代表每次点击按钮【Run】执行生产;选择周期生产模式,需要填写运行总时间和运行时间间隔。
- Header:输入 Header 的 key,value
- Options:选择 Froce Partition,代表消息仅发送到这些选择的 Partition。选择数据压缩格式。选择 Acks 参数,none 意思是消息发送了就认为发送成功;leader 意思是 leader 接收到消息(不管 follower 有没有同步成功)认为消息发送成功;all 意思是所有的 follower 消息同步成功认为是消息发送成功
步骤 3:点击按钮【Run】,生产测试开始,可以从右侧看到生产测试的信息
5.4.9.2、消费测试
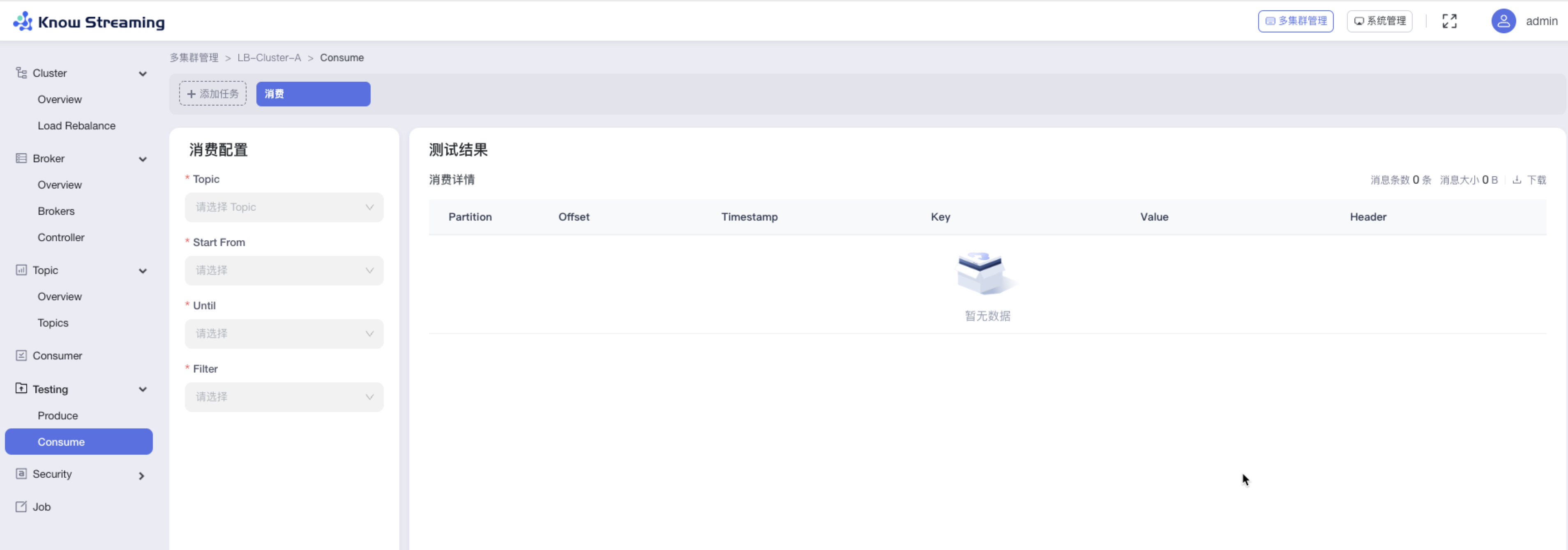
步骤 1:点击“多集群管理”>“集群卡片”>“Testing”>“Consume”
步骤 2:消费配置
- Topic:选择数据从哪个 topic 进行消费
- Start From:选择数据从什么地方开始消费,可以根据时间选择或者根据 Offset 进行选择
- Until:选择消费截止到什么地方,可以根据时间或者 offset 或者消息数等进行选择
- Filter:选择过滤器的规则。包含/不包含某【key,value】;等于/大于/小于多少条消息
步骤 3:点击按钮【Run】,消费测试开始,可以在右边看到消费的明细信息
5.4.10、Security
注意:只有在开启集群认证的情况下才能够使用 Security 功能
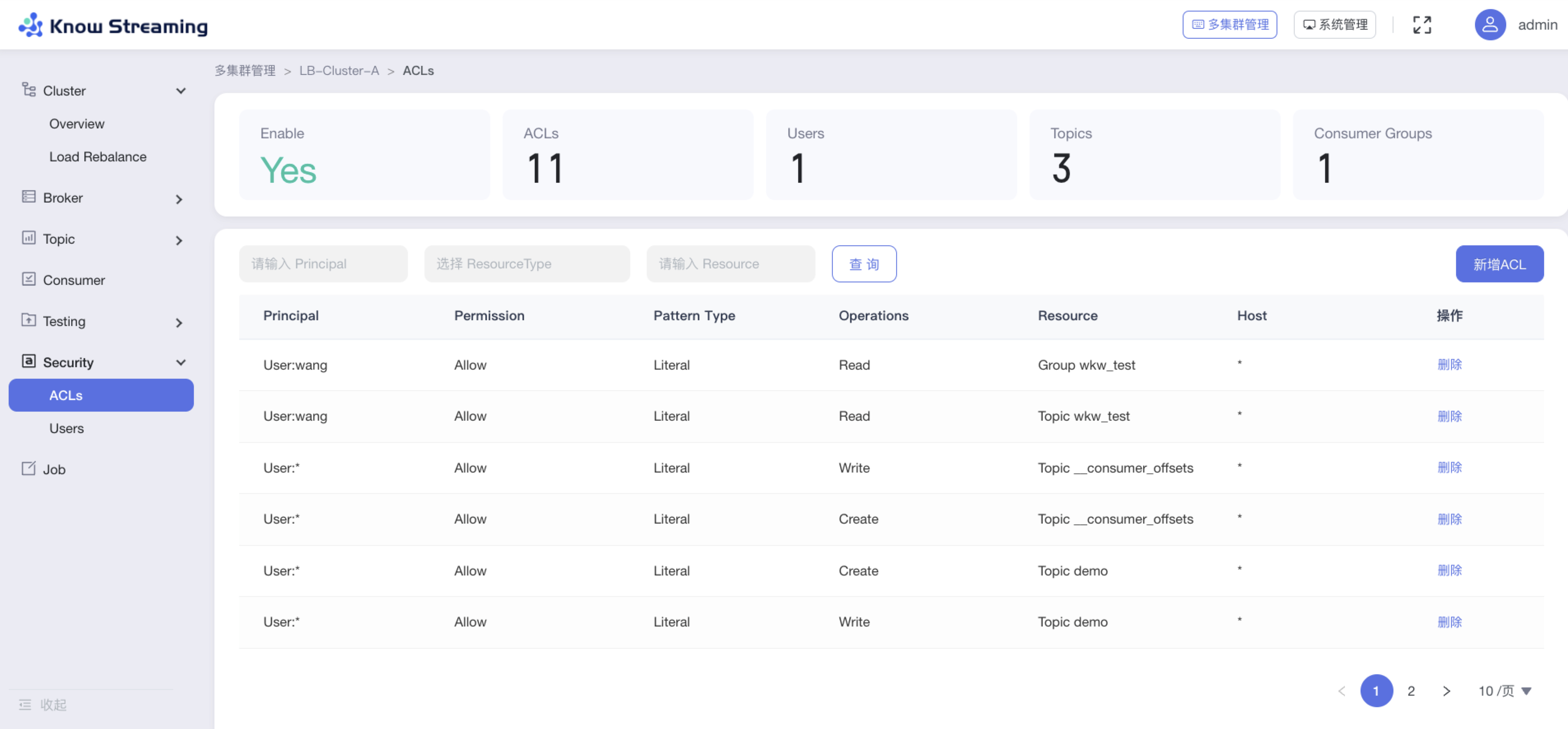
5.4.10.1、查看 ACL 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
步骤 2:ACL 概览信息包括以下内容
- Enable:是否可用
- ACLs:ACL 总数
- Users:User 总数
- Topics:Topic 总数
- Consumer Groups:Consumer Group 总数
- ACL 列表
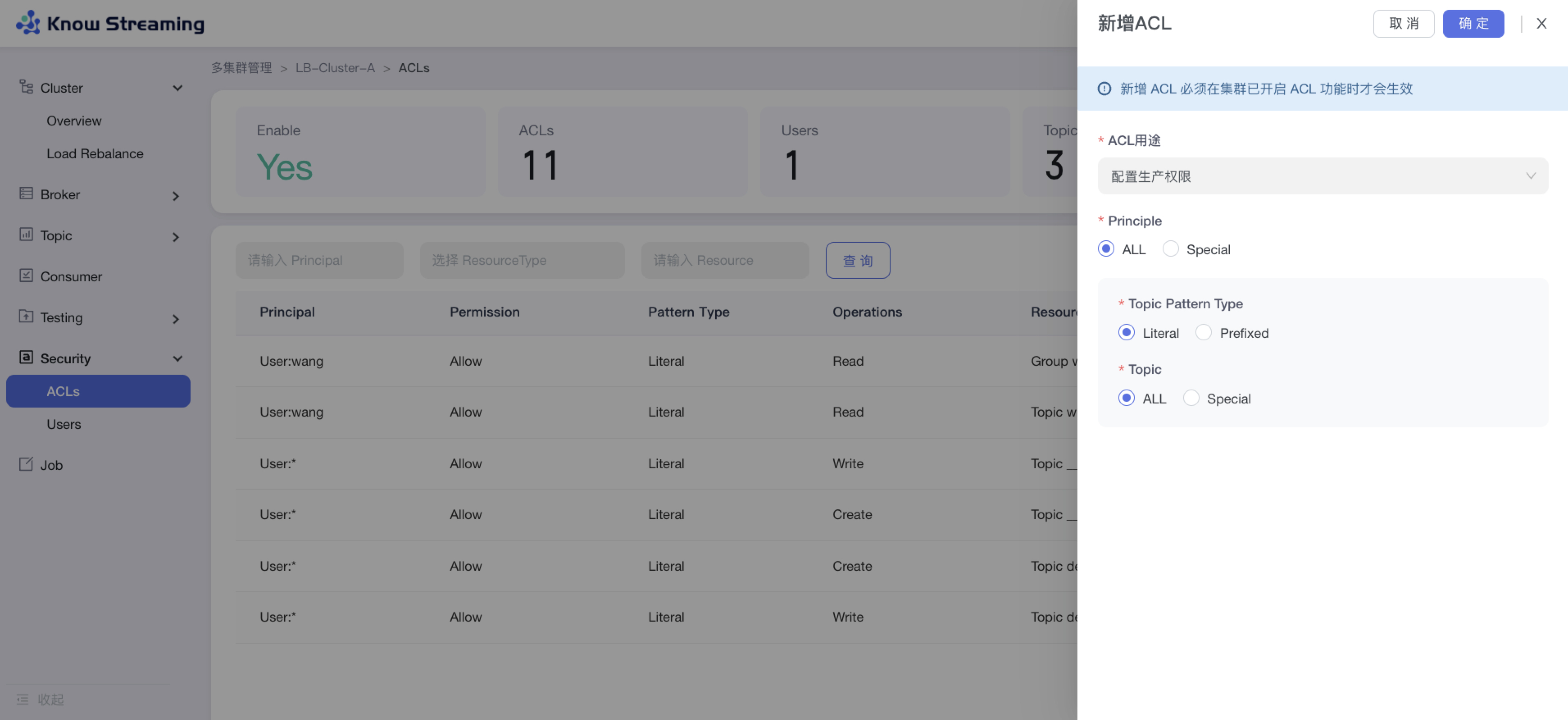
5.4.10.2、新增 ACl
步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 ACL”
步骤 2:输入 ACL 配置参数
- ACL 用途:生产权限、消费权限、自定义权限
- 生产权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic
- 消费权限时:可选择应用于所有 Kafka User 或者特定 Kafka User;可选择应用于所有 Topic 或者特定 Topic;可选择应用于所有 Consumer Group 或者特定 Consumer Group
步骤 3:点击“确定”,新增 ACL 成功
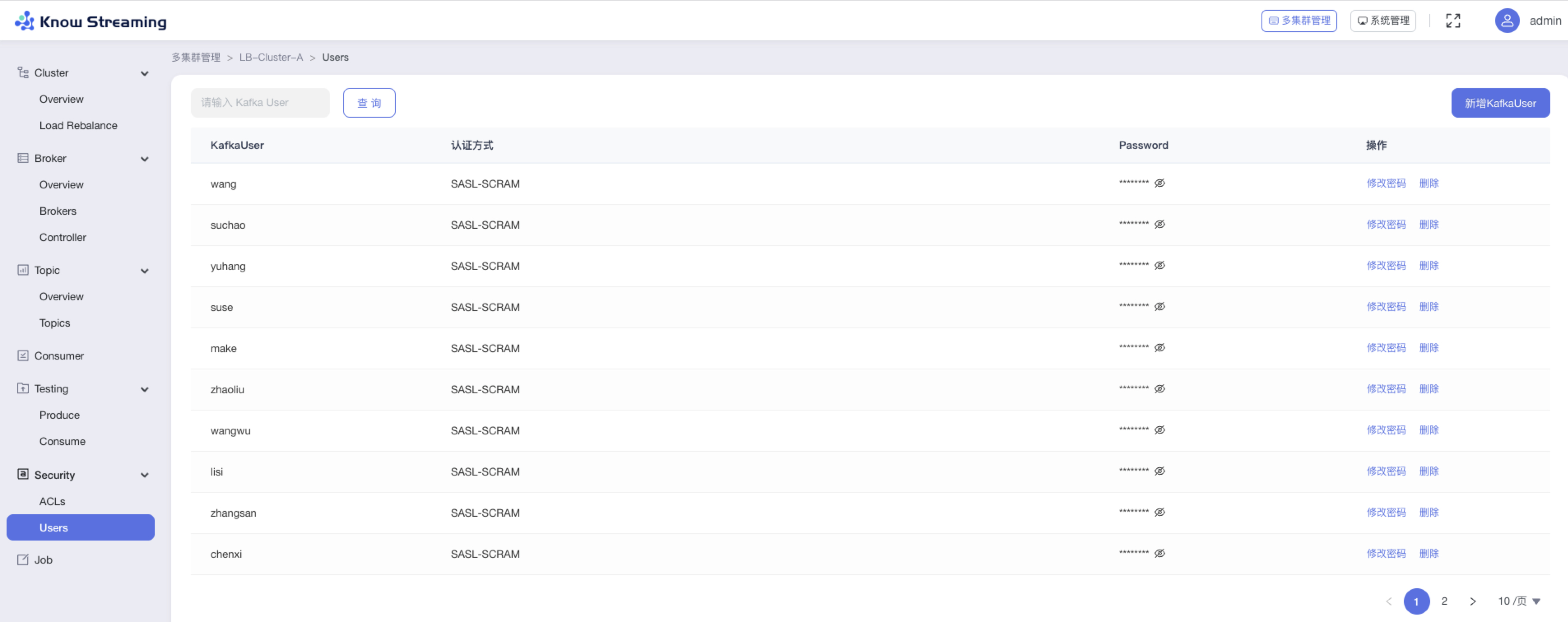
5.4.10.3、查看 User 信息
步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“ACLs”
步骤 2:User 列表展示内容包括“Kafka User 名称”、“认证方式”、“passwprd”、操作项”修改密码“、”操作项“删除”
步骤 3:筛选框输入“Kafka User”可筛选出列表中相关 Kafka User
5.4.10.4、新增 Kafka User
步骤 1:点击“多集群管理”>“集群卡片”>“Security”>“Users”>“新增 Kafka User”
步骤 2:输入 Kafka User 名称、认证方式、密码
步骤 3:点击“确定”,新增 Kafka User 成功
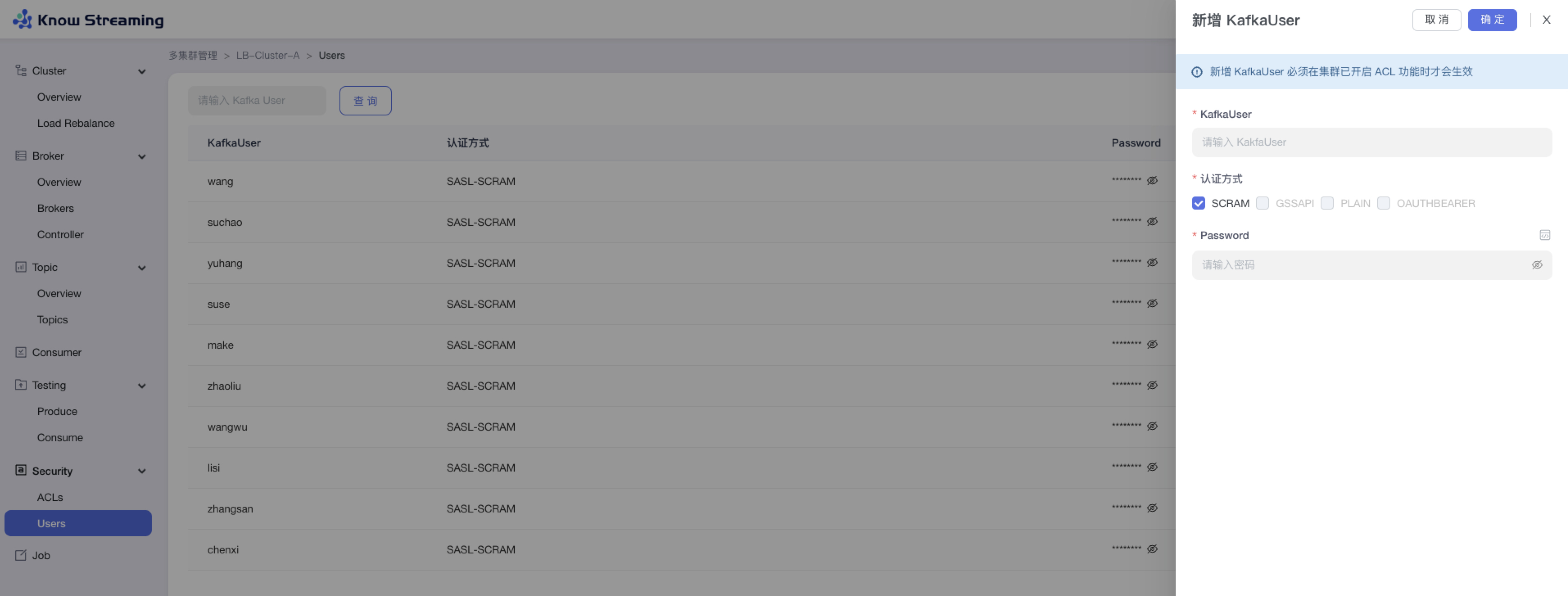
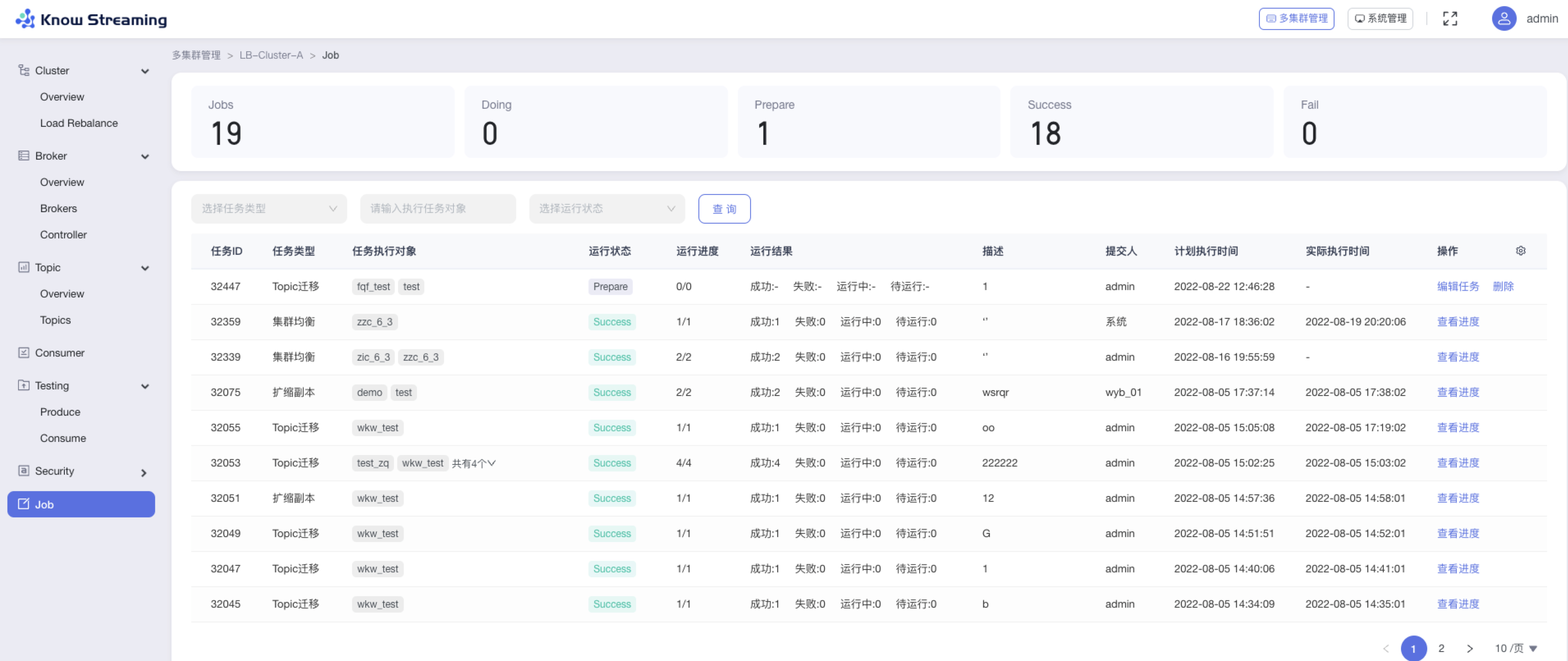
5.4.11、Job
5.4.11.1、查看 Job 概览信息
步骤 1:点击“多集群管理”>“集群卡片”>“Job“
步骤 2:Job 概览信息包括以下内容
- Jobs:Job 总数
- Doing:正在运行的 Job 总数
- Prepare:准备运行的 Job 总数
- Success:运行成功的 Job 总数
- Fail:运行失败的 Job 总数
- Job 列表
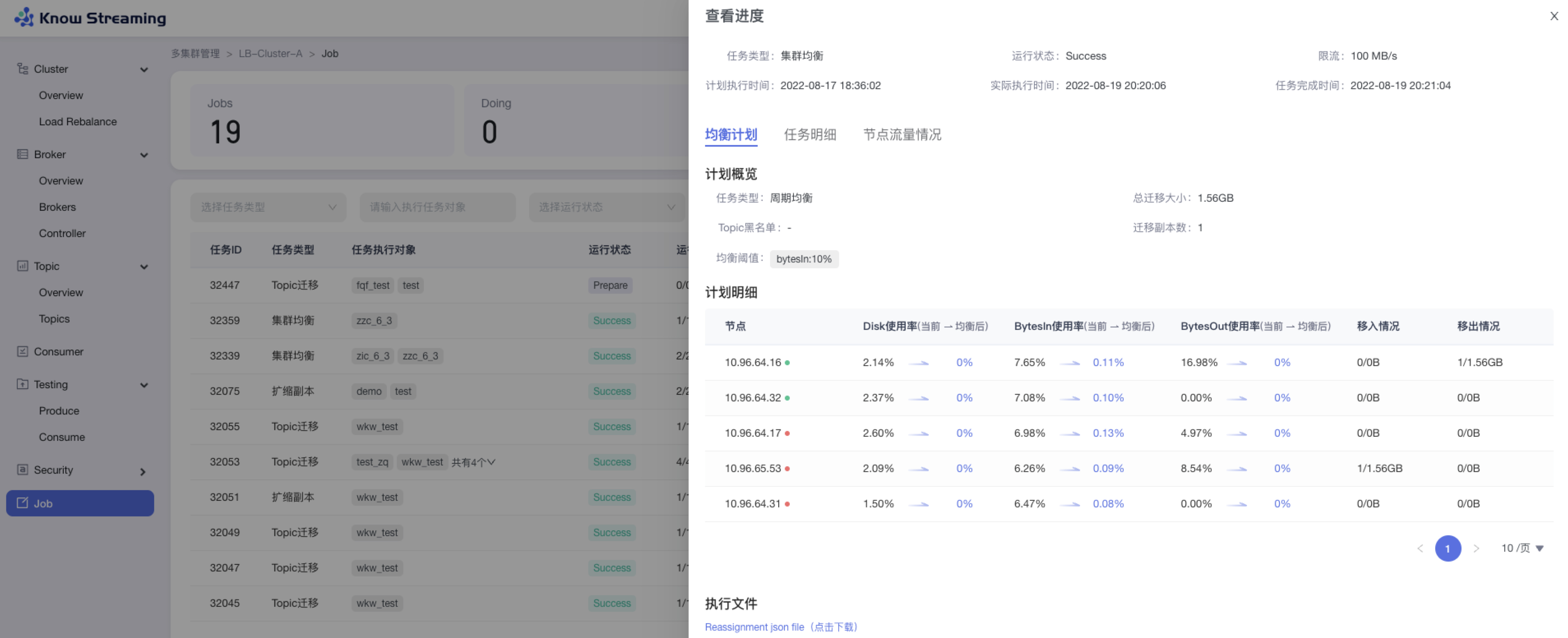
5.4.11.2、Job 查看进度
Doing 状态下的任务可以查看进度
步骤 1:点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“查看进度”>“查看进度”抽屉
步骤 2:
- 均衡任务:任务基本信息、均衡计划、任务执行明细信息
- 扩缩副本:任务基本信息、任务执行明细信息、节点流量情况
- Topic 迁移:任务基本信息、任务执行明细信息、节点流量情况
5.4.11.3、Job 编辑任务
Prepare 状态下的任务可以进行编辑
点击“多集群管理”>“集群卡片”>“Job”>“Job”列表>操作项“编辑”
对任务执行的参数进行重新配置
- 集群均衡:可以对指标计算周期、均衡维度、topic 黑名单、运行配置等参数重新设置
- Topic 迁移:可以对 topic 需要迁移的 partition、迁移数据的时间范围、目标 broker 节点、限流值、执行时间、描述等参数重新配置
- topic 扩缩副本:可以对最终副本数、限流值、任务执行时间、描述等参数重新配置
点击“确定”,编辑任务成功
6.1、本地源码启动手册
6.1.1、打包方式
Know Streaming 采用前后端分离的开发模式,使用 Maven 对项目进行统一的构建管理。maven 在打包构建过程中,会将前后端代码一并打包生成最终的安装包。
Know Streaming 除了使用安装包启动之外,还可以通过本地源码启动完整的带前端页面的项目,下面我们正式开始介绍本地源码如何启动 Know Streaming。
6.1.2、环境要求
系统支持
windows7+、Linux、Mac
环境依赖
- Maven 3.6.3
- Node v12.20.0
- Java 8+
- MySQL 5.7
- Idea
- Elasticsearch 7.6
- Git
6.1.3、环境初始化
安装好环境信息之后,还需要初始化 MySQL 与 Elasticsearch 信息,包括:
- 初始化 MySQL 表及数据
- 初始化 Elasticsearch 索引
具体见:单机部署手册 中的最后一步,部署 KnowStreaming 服务中的初始化相关工作。
6.1.4、本地启动
第一步:本地打包
执行 mvn install 可对项目进行前后端同时进行打包,通过该命令,除了可以对后端进行打包之外,还可以将前端相关的静态资源文件也一并打包出来。
第二步:修改配置
# 修改 km-rest/src/main/resources/application.yml 中相关的配置
# 修改MySQL的配置,中间省略了一些非必需修改的配置
spring:
datasource:
know-streaming:
jdbc-url: 修改为实际MYSQL地址
username: 修改为实际MYSQL用户名
password: 修改为实际MYSQL密码
logi-job:
jdbc-url: 修改为实际MYSQL地址
username: 修改为实际MYSQL用户名
password: 修改为实际MYSQL密码
logi-security:
jdbc-url: 修改为实际MYSQL地址
username: 修改为实际MYSQL用户名
password: 修改为实际MYSQL密码
# 修改ES的配置,中间省略了一些非必需修改的配置
es.client.address: 修改为实际ES地址
第三步:配置 IDEA
Know Streaming的 Main 方法在:
km-rest/src/main/java/com/xiaojukeji/know/streaming/km/rest/KnowStreaming.java
IDEA 更多具体的配置如下图所示:
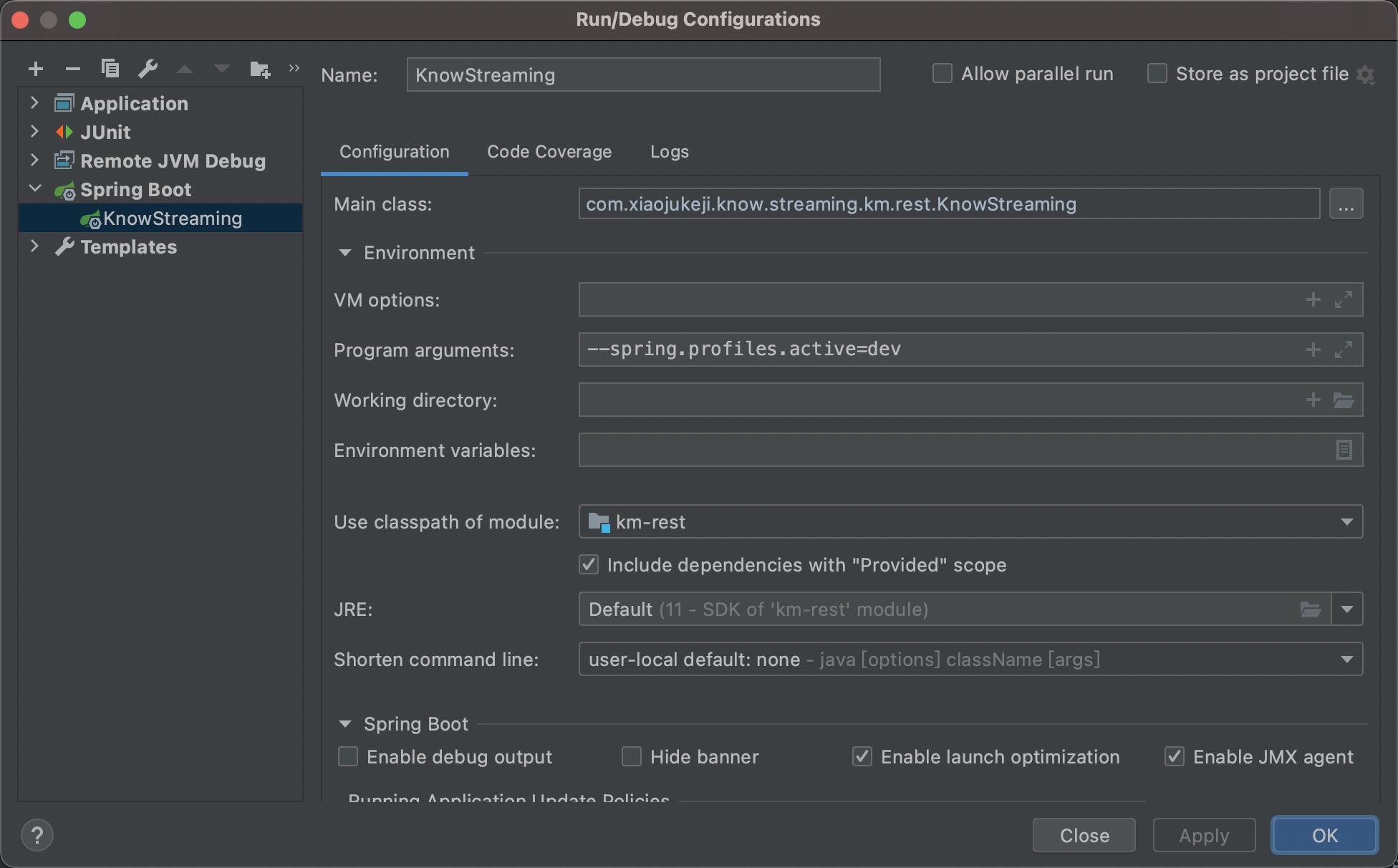
第四步:启动项目
最后就是启动项目,在本地 console 中输出了 KnowStreaming-KM started 则表示我们已经成功启动 Know Streaming 了。
6.1.5、本地访问
Know Streaming 启动之后,可以访问一些信息,包括:
- 产品页面:http://localhost:8080 ,默认账号密码:
admin/admin2022_进行登录。v3.0.0-beta.2版本开始,默认账号密码为admin/admin; - 接口地址:http://localhost:8080/swagger-ui.html 查看后端提供的相关接口。
更多信息,详见:KnowStreaming 官网
6.2、版本升级手册
注意:
- 如果想升级至具体版本,需要将你当前版本至你期望使用版本的变更统统执行一遍,然后才能正常使用。
- 如果中间某个版本没有升级信息,则表示该版本直接替换安装包即可从前一个版本升级至当前版本。
升级至 master 版本
SQL 变更
ALTER TABLE `logi_security_user`
CHANGE COLUMN `phone` `phone` VARCHAR(20) NOT NULL DEFAULT '' COMMENT 'mobile' ;
升级至 3.2.0 版本
配置变更
# 新增如下配置
spring:
logi-job: # know-streaming 依赖的 logi-job 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
enable: true # true表示开启job任务, false表关闭。KS在部署上可以考虑部署两套服务,一套处理前端请求,一套执行job任务,此时可以通过该字段进行控制
# 线程池大小相关配置
thread-pool:
es:
search: # es查询线程池
thread-num: 20 # 线程池大小
queue-size: 10000 # 队列大小
# 客户端池大小相关配置
client-pool:
kafka-admin:
client-cnt: 1 # 每个Kafka集群创建的KafkaAdminClient数
# ES客户端配置
es:
index:
expire: 15 # 索引过期天数,15表示超过15天的索引会被KS过期删除
SQL 变更
DROP TABLE IF EXISTS `ks_kc_connect_cluster`;
CREATE TABLE `ks_kc_connect_cluster` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Connect集群ID',
`kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
`name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群名称',
`group_name` varchar(128) NOT NULL DEFAULT '' COMMENT '集群Group名称',
`cluster_url` varchar(1024) NOT NULL DEFAULT '' COMMENT '集群地址',
`member_leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL地址',
`version` varchar(64) NOT NULL DEFAULT '' COMMENT 'connect版本',
`jmx_properties` text COMMENT 'JMX配置',
`state` tinyint(4) NOT NULL DEFAULT '1' COMMENT '集群使用的消费组状态,也表示集群状态:-1 Unknown,0 ReBalance,1 Active,2 Dead,3 Empty',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '接入时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_id_group_name` (`id`,`group_name`),
UNIQUE KEY `uniq_name_kafka_cluster` (`name`,`kafka_cluster_phy_id`),
KEY `idx_kafka_cluster_phy_id` (`kafka_cluster_phy_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connect集群信息表';
DROP TABLE IF EXISTS `ks_kc_connector`;
CREATE TABLE `ks_kc_connector` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
`connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
`connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
`connector_class_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector类',
`connector_type` varchar(32) NOT NULL DEFAULT '' COMMENT 'Connector类型',
`state` varchar(45) NOT NULL DEFAULT '' COMMENT '状态',
`topics` text COMMENT '访问过的Topics',
`task_count` int(11) NOT NULL DEFAULT '0' COMMENT '任务数',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_connect_cluster_id_connector_name` (`connect_cluster_id`,`connector_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Connector信息表';
DROP TABLE IF EXISTS `ks_kc_worker`;
CREATE TABLE `ks_kc_worker` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
`connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
`member_id` varchar(512) NOT NULL DEFAULT '' COMMENT '成员ID',
`host` varchar(128) NOT NULL DEFAULT '' COMMENT '主机名',
`jmx_port` int(16) NOT NULL DEFAULT '-1' COMMENT 'Jmx端口',
`url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'URL信息',
`leader_url` varchar(1024) NOT NULL DEFAULT '' COMMENT 'leaderURL信息',
`leader` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1是leader,0不是leader',
`worker_id` varchar(128) NOT NULL COMMENT 'worker地址',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_cluster_id_member_id` (`connect_cluster_id`,`member_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='worker信息表';
DROP TABLE IF EXISTS `ks_kc_worker_connector`;
CREATE TABLE `ks_kc_worker_connector` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`kafka_cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Kafka集群ID',
`connect_cluster_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT 'Connect集群ID',
`connector_name` varchar(512) NOT NULL DEFAULT '' COMMENT 'Connector名称',
`worker_member_id` varchar(256) NOT NULL DEFAULT '',
`task_id` int(16) NOT NULL DEFAULT '-1' COMMENT 'Task的ID',
`state` varchar(128) DEFAULT NULL COMMENT '任务状态',
`worker_id` varchar(128) DEFAULT NULL COMMENT 'worker信息',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_relation` (`connect_cluster_id`,`connector_name`,`task_id`,`worker_member_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Worker和Connector关系表';
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_FAILED_TASK_COUNT', '{\"value\" : 1}', 'connector失败状态的任务数量', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECTOR_UNASSIGNED_TASK_COUNT', '{\"value\" : 1}', 'connector未被分配的任务数量', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_CONNECT_CLUSTER_TASK_STARTUP_FAILURE_PERCENTAGE', '{\"value\" : 0.05}', 'Connect集群任务启动失败概率', 'admin');
升级至 v3.1.0 版本
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_BRAIN_SPLIT', '{ \"value\": 1} ', 'ZK 脑裂', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_OUTSTANDING_REQUESTS', '{ \"amount\": 100, \"ratio\":0.8} ', 'ZK Outstanding 请求堆积数', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_WATCH_COUNT', '{ \"amount\": 100000, \"ratio\": 0.8 } ', 'ZK WatchCount 数', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_ALIVE_CONNECTIONS', '{ \"amount\": 10000, \"ratio\": 0.8 } ', 'ZK 连接数', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_APPROXIMATE_DATA_SIZE', '{ \"amount\": 524288000, \"ratio\": 0.8 } ', 'ZK 数据大小(Byte)', 'admin');
INSERT INTO `ks_km_platform_cluster_config` (`cluster_id`, `value_group`, `value_name`, `value`, `description`, `operator`) VALUES ('-1', 'HEALTH', 'HC_ZK_SENT_RATE', '{ \"amount\": 500000, \"ratio\": 0.8 } ', 'ZK 发包数', 'admin');
升级至 v3.0.1 版本
ES 索引模版
# 新增 ks_kafka_zookeeper_metric 索引模版。
# 可通过再次执行 bin/init_es_template.sh 脚本,创建该索引模版。
# 索引模版内容
PUT _template/ks_kafka_zookeeper_metric
{
"order" : 10,
"index_patterns" : [
"ks_kafka_zookeeper_metric*"
],
"settings" : {
"index" : {
"number_of_shards" : "10"
}
},
"mappings" : {
"properties" : {
"routingValue" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"clusterPhyId" : {
"type" : "long"
},
"metrics" : {
"properties" : {
"AvgRequestLatency" : {
"type" : "double"
},
"MinRequestLatency" : {
"type" : "double"
},
"MaxRequestLatency" : {
"type" : "double"
},
"OutstandingRequests" : {
"type" : "double"
},
"NodeCount" : {
"type" : "double"
},
"WatchCount" : {
"type" : "double"
},
"NumAliveConnections" : {
"type" : "double"
},
"PacketsReceived" : {
"type" : "double"
},
"PacketsSent" : {
"type" : "double"
},
"EphemeralsCount" : {
"type" : "double"
},
"ApproximateDataSize" : {
"type" : "double"
},
"OpenFileDescriptorCount" : {
"type" : "double"
},
"MaxFileDescriptorCount" : {
"type" : "double"
}
}
},
"key" : {
"type" : "text",
"fields" : {
"keyword" : {
"ignore_above" : 256,
"type" : "keyword"
}
}
},
"timestamp" : {
"format" : "yyyy-MM-dd HH:mm:ss Z||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd HH:mm:ss.SSS Z||yyyy-MM-dd HH:mm:ss.SSS||yyyy-MM-dd HH:mm:ss,SSS||yyyy/MM/dd HH:mm:ss||yyyy-MM-dd HH:mm:ss,SSS Z||yyyy/MM/dd HH:mm:ss,SSS Z||epoch_millis",
"type" : "date"
}
}
},
"aliases" : { }
}
SQL 变更
DROP TABLE IF EXISTS `ks_km_zookeeper`;
CREATE TABLE `ks_km_zookeeper` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '物理集群ID',
`host` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper主机名',
`port` int(16) NOT NULL DEFAULT '-1' COMMENT 'zookeeper端口',
`role` varchar(16) NOT NULL DEFAULT '' COMMENT '角色, leader follower observer',
`version` varchar(128) NOT NULL DEFAULT '' COMMENT 'zookeeper版本',
`status` int(16) NOT NULL DEFAULT '0' COMMENT '状态: 1存活,0未存活,11存活但是4字命令使用不了',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_cluster_phy_id_host_port` (`cluster_phy_id`,`host`, `port`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Zookeeper信息表';
DROP TABLE IF EXISTS `ks_km_group`;
CREATE TABLE `ks_km_group` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'id',
`cluster_phy_id` bigint(20) NOT NULL DEFAULT '-1' COMMENT '集群id',
`name` varchar(192) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'Group名称',
`member_count` int(11) unsigned NOT NULL DEFAULT '0' COMMENT '成员数',
`topic_members` text CHARACTER SET utf8 COMMENT 'group消费的topic列表',
`partition_assignor` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '分配策略',
`coordinator_id` int(11) NOT NULL COMMENT 'group协调器brokerId',
`type` int(11) NOT NULL COMMENT 'group类型 0:consumer 1:connector',
`state` varchar(64) CHARACTER SET utf8 NOT NULL DEFAULT '' COMMENT '状态',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_cluster_phy_id_name` (`cluster_phy_id`,`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='Group信息表';
升级至 v3.0.0 版本
SQL 变更
ALTER TABLE `ks_km_physical_cluster`
ADD COLUMN `zk_properties` TEXT NULL COMMENT 'ZK配置' AFTER `jmx_properties`;
升级至 v3.0.0-beta.2版本
配置变更
# 新增配置
spring:
logi-security: # know-streaming 依赖的 logi-security 模块的数据库的配置,默认与 know-streaming 的数据库配置保持一致即可
login-extend-bean-name: logiSecurityDefaultLoginExtendImpl # 使用的登录系统Service的Bean名称,无需修改
# 线程池大小相关配置,在task模块中,新增了三类线程池,
# 从而减少不同类型任务之间的相互影响,以及减少对logi-job内的线程池的影响
thread-pool:
task: # 任务模块的配置
metrics: # metrics采集任务配置
thread-num: 18 # metrics采集任务线程池核心线程数
queue-size: 180 # metrics采集任务线程池队列大小
metadata: # metadata同步任务配置
thread-num: 27 # metadata同步任务线程池核心线程数
queue-size: 270 # metadata同步任务线程池队列大小
common: # 剩余其他任务配置
thread-num: 15 # 剩余其他任务线程池核心线程数
queue-size: 150 # 剩余其他任务线程池队列大小
# 删除配置,下列配置将不再使用
thread-pool:
task: # 任务模块的配置
heaven: # 采集任务配置
thread-num: 20 # 采集任务线程池核心线程数
queue-size: 1000 # 采集任务线程池队列大小
SQL 变更
-- 多集群管理权限2022-09-06新增
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2000', '多集群管理查看', '1593', '1', '2', '多集群管理查看', '0', 'know-streaming');
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2002', 'Topic-迁移副本', '1593', '1', '2', 'Topic-迁移副本', '0', 'know-streaming');
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2004', 'Topic-扩缩副本', '1593', '1', '2', 'Topic-扩缩副本', '0', 'know-streaming');
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2006', 'Cluster-LoadReBalance-周期均衡', '1593', '1', '2', 'Cluster-LoadReBalance-周期均衡', '0', 'know-streaming');
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2008', 'Cluster-LoadReBalance-立即均衡', '1593', '1', '2', 'Cluster-LoadReBalance-立即均衡', '0', 'know-streaming');
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('2010', 'Cluster-LoadReBalance-设置集群规格', '1593', '1', '2', 'Cluster-LoadReBalance-设置集群规格', '0', 'know-streaming');
-- 系统管理权限2022-09-06新增
INSERT INTO `logi_security_permission` (`id`, `permission_name`, `parent_id`, `leaf`, `level`, `description`, `is_delete`, `app_name`) VALUES ('3000', '系统管理查看', '1595', '1', '2', '系统管理查看', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2000', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2002', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2004', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2006', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2008', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '2010', '0', 'know-streaming');
INSERT INTO `logi_security_role_permission` (`role_id`, `permission_id`, `is_delete`, `app_name`) VALUES ('1677', '3000', '0', 'know-streaming');
-- 修改字段长度
ALTER TABLE `logi_security_oplog`
CHANGE COLUMN `operator_ip` `operator_ip` VARCHAR(64) NOT NULL COMMENT '操作者ip' ,
CHANGE COLUMN `operator` `operator` VARCHAR(64) NULL DEFAULT NULL COMMENT '操作者账号' ,
CHANGE COLUMN `operate_page` `operate_page` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作页面' ,
CHANGE COLUMN `operate_type` `operate_type` VARCHAR(64) NOT NULL COMMENT '操作类型' ,
CHANGE COLUMN `target_type` `target_type` VARCHAR(64) NOT NULL COMMENT '对象分类' ,
CHANGE COLUMN `target` `target` VARCHAR(1024) NOT NULL COMMENT '操作对象' ,
CHANGE COLUMN `operation_methods` `operation_methods` VARCHAR(64) NOT NULL DEFAULT '' COMMENT '操作方式' ;
升级至 v3.0.0-beta.1版本
SQL 变更
1、在ks_km_broker表增加了一个监听信息字段。 2、为logi_security_oplog表 operation_methods 字段设置默认值''。 因此需要执行下面的 sql 对数据库表进行更新。
ALTER TABLE `ks_km_broker`
ADD COLUMN `endpoint_map` VARCHAR(1024) NOT NULL DEFAULT '' COMMENT '监听信息' AFTER `update_time`;
ALTER TABLE `logi_security_oplog`
ALTER COLUMN `operation_methods` set default '';
2.x版本 升级至 v3.0.0-beta.0版本
升级步骤:
- 依旧使用**
2.x 版本的 DB**,在上面初始化 3.0.0 版本所需数据库表结构及数据; - 将 2.x 版本中的集群,在 3.0.0 版本,手动逐一接入;
- 将 Topic 业务数据,迁移至 3.0.0 表中,详见下方 SQL;
注意事项
- 建议升级 3.0.0 版本过程中,保留 2.x 版本的使用,待 3.0.0 版本稳定使用后,再下线 2.x 版本;
- 3.0.0 版本仅需要
集群信息及Topic的描述信息。2.x 版本的 DB 的其他数据 3.0.0 版本都不需要; - 部署 3.0.0 版本之后,集群、Topic 等指标数据都为空,3.0.0 版本会周期进行采集,运行一段时间之后就会有该数据了,因此不会将 2.x 中的指标数据进行迁移;
迁移数据
-- 迁移Topic的备注信息。
-- 需在 3.0.0 部署完成后,再执行该SQL。
-- 考虑到 2.x 版本中还存在增量数据,因此建议改SQL周期执行,是的增量数据也能被迁移至 3.0.0 版本中。
UPDATE ks_km_topic
INNER JOIN
(SELECT
topic.cluster_id AS cluster_id,
topic.topic_name AS topic_name,
topic.description AS description
FROM topic WHERE description != ''
) AS t
ON ks_km_topic.cluster_phy_id = t.cluster_id
AND ks_km_topic.topic_name = t.topic_name
AND ks_km_topic.id > 0
SET ks_km_topic.description = t.description;
